 English
English
The AI revolution is reshaping data center infrastructure at an unprecedented pace. High-speed optical transceivers have become the backbone of low-latency, high-bandwidth connectivity required by modern AI workloads. As 800G transceivers enter large-scale deployment and 1.6T solutions move closer to early commercialization, data center operators and hyperscalers face a critical decision: which transceiver generation best aligns with their 2026 AI workloads, infrastructure maturity, and cost targets?
This article examines the technical trade-offs, application fit, and deployment considerations of 800G and 1.6T transceivers, providing a practical, data-driven framework for selecting the right option for next-generation AI data centers.
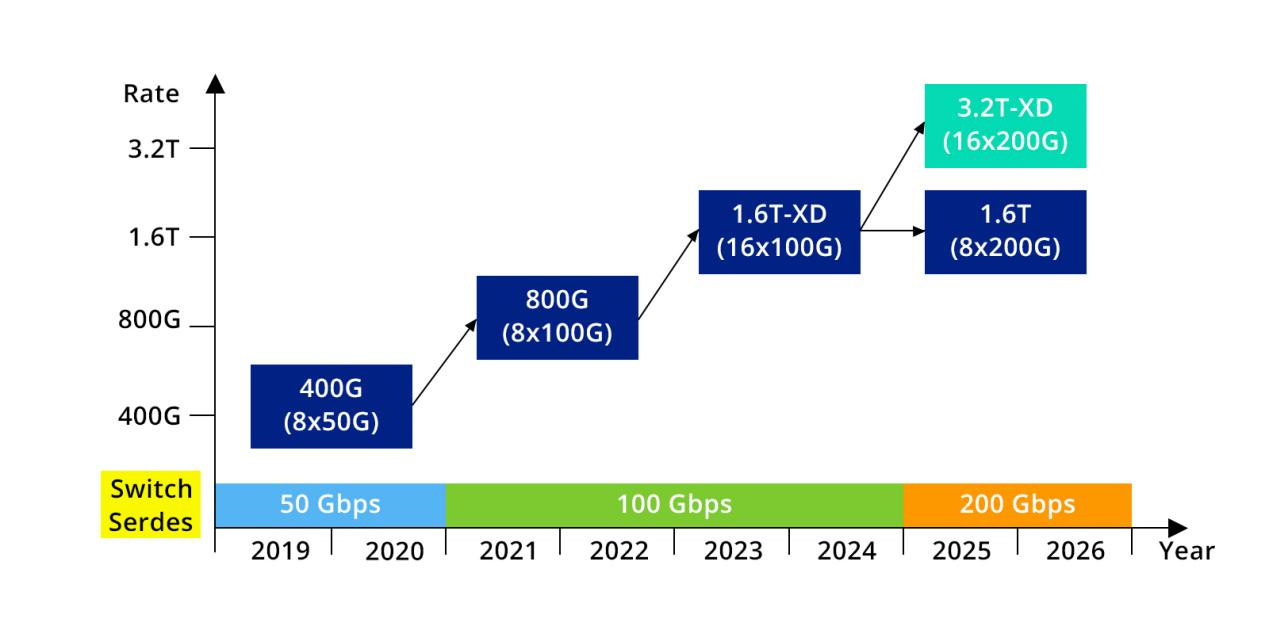
Figure 1: Evolution Roadmap of Transceiver Rates and SerDes Speed
Core Differences: 800G vs. 1.6T (Speed, Power Consumption, Cost)
To determine which transceiver best fits an AI data center, it is essential to understand the fundamental differences between 800G and 1.6T transceivers.
Speed and Bandwidth Density
800G transceivers deliver a maximum data rate of 800 gigabits per second (Gbps), typically implemented as 8 lanes of 100G. In contrast, 1.6T transceivers double that capacity to 1.6 terabits per second (Tbps), commonly achieved via 8 lanes of 200G or 16 lanes of 100G.
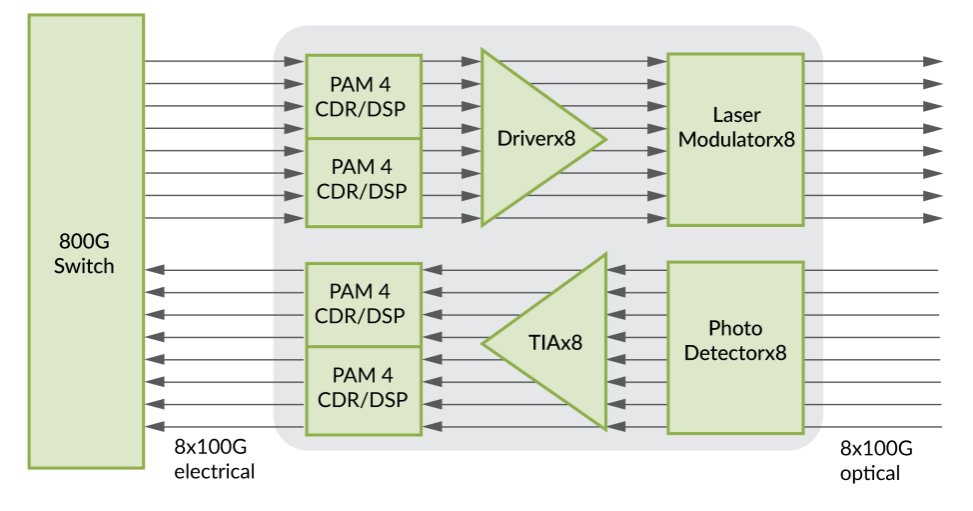
Figure 2: 800G (X8) Transceiver Internal Architecture (Source: Juniper)
For bandwidth-bound AI training workloads—such as large-scale distributed LLM training—1.6T transceiver can significantly reduce inter-node communication time in bandwidth-bound training scenarios. Hyperscaler evaluations often cite reductions in data transfer overhead on the order of 30–40% compared with 800G, depending on network topology, collective communication patterns, and GPU-to-NIC ratios.
Power Consumption and Efficiency
Power efficiency is a critical metric in high-density AI racks. Current-generation 800G modules (e.g., QSFP-DD800, OSFP 800G) typically consume 12 - 15 watts per module, while early 1.6T implementations (including OSFP-XD and QSFP-DD1600 form factors) generally fall in the 18 - 22 watt range.
When normalized by bandwidth, however, 1.6T shows a modest efficiency advantage. Typical figures place 1.6T at approximately 0.011–0.014 W/Gbps, compared with 0.015–0.019 W/Gbps for 800G. This watts-per-Gbps metric is increasingly important for operators seeking to improve long-term energy efficiency rather than focusing solely on absolute power draw.
Cost and Ecosystem Maturity
Cost remains one of the strongest differentiators in 2026. Thanks to large-scale production and a mature ecosystem, 800G transceivers have reached a cost-efficient phase, with pricing well optimized for high-volume deployments. In contrast, 1.6T modules remain in the early stages of commercialization. Limited production scale, advanced optical components, and lower yield rates result in significantly higher per-module costs compared with 800G, particularly in initial deployments.
Beyond optics, 1.6T adoption often requires next-generation switch platforms and ASICs, resulting in a noticeably higher upfront infrastructure investment. From a form-factor perspective, 800G relies on well-established QSFP-DD and OSFP designs, while 1.6T frequently uses newer, larger form factors such as OSFP-XD, which may present mechanical or thermal constraints in legacy rack designs.
To better understand the underlying technologies, you may also explore silicon photonics for 800G interconnects and how it compares with emerging architectures like CPO and LPO optics.
Application Scenarios: When to Choose 800G vs. 1.6T
The optimal choice between 800G and 1.6T depends primarily on data center scale, workload characteristics, and cost sensitivity.
When 800G Is the Better Fit
800G transceivers are well suited for mid-sized data centers, enterprise AI deployments, and edge or regional facilities where technology maturity and cost efficiency are paramount. They perform exceptionally well in inference-heavy environments, small-to-medium LLM training clusters, and traditional spine-leaf architectures with moderate east-west traffic.
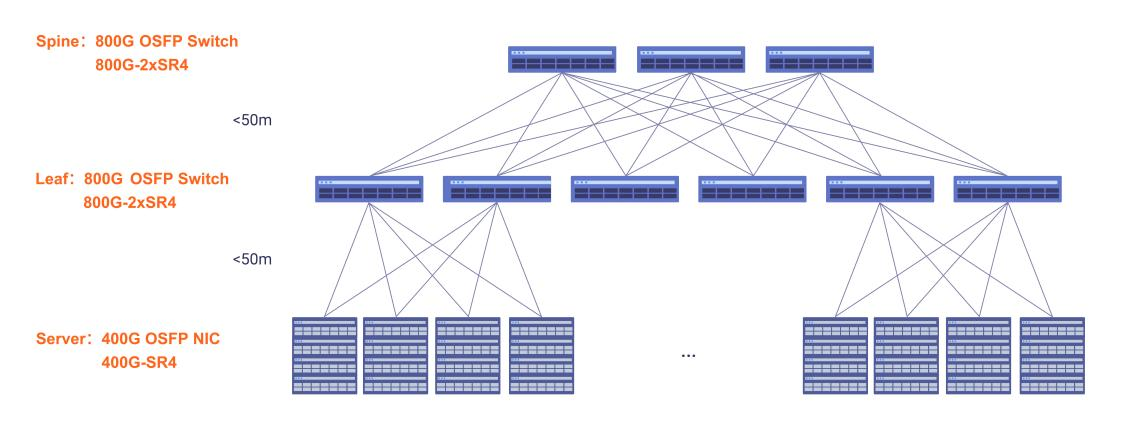
Figure 3: 800G Network Topology for AI Data Centers
For example, a regional cloud provider supporting AI-powered customer service or recommendation engines can fully meet performance requirements with 800G, avoiding the premium and integration complexity of 1.6T. For operators upgrading from 400G, 800G also represents a low-risk, incremental step that leverages existing operational experience.
When 1.6T Makes Sense
1.6T transceivers are designed for hyperscale AI factories and large LLM training clusters where bandwidth density is a first-order constraint. In such environments, higher per-port bandwidth can reduce the total number of switch ports, transceivers, and fiber links required, simplifying network architecture at scale.
In a hypothetical 10,000-GPU training cluster, migrating from 800G to 1.6T at the spine layer could reduce the number of required optical modules by up to 50%. While per-module costs are higher, savings in cabling, rack space, and operational complexity can partially offset the initial investment. For operators planning expansions beyond 2027, 1.6T also provides a clearer runway for next-generation AI models with rapidly growing communication demands.
Deployment Considerations: Compatibility, Upgrade Costs, Supply Chain Readiness
Before committing to either 800G or 1.6T, data center operators must evaluate three practical deployment factors.
Hardware Compatibility
800G transceivers are broadly compatible with current-generation switches that support QSFP-DD or OSFP, making them a relatively straightforward upgrade for 400G-capable networks. In contrast, 1.6T requires switches built around next-generation, 1.6T-class ASICs (such as Broadcom Tomahawk 5 or equivalent platforms), often necessitating a full switch refresh.
Fiber infrastructure may also need attention. While some 1.6T implementations can reuse existing fiber, certain multimode deployments may require upgrades (for example, from OM4 to OM5), depending on reach requirements and modulation schemes.
Total Upgrade Costs
For 800G deployments, upgrade costs are primarily driven by the optical modules themselves, along with limited firmware or configuration adjustments. As a result, the overall per-port investment remains relatively contained and predictable.
In contrast, 1.6T deployments introduce multiple additional cost layers, including new switch platforms or ASICs, potential fiber infrastructure upgrades, and increased installation and validation effort. These factors collectively result in a substantially higher per-port investment compared with 800G.
Supply Chain Readiness
By 2026, 800G enjoys a robust and diversified supply chain, with multiple vendors producing modules at scale and lead times typically ranging from 4-8 weeks. The 1.6T ecosystem remains more constrained, with fewer qualified suppliers, longer lead times (often 12-16 weeks), and dependence on advanced components such as high-speed EML lasers and thin-film lithium niobate modulators. These factors introduce additional risk for projects with tight deployment schedules.
Conclusion: Practical Recommendations for 2026
There is no universal answer to the 800G versus 1.6T decision. The optimal choice depends on workload characteristics, infrastructure maturity, and long-term growth plans.
Choose 800G if you operate a mid-sized or enterprise AI environment, prioritize proven technology and predictable costs, or primarily run inference and moderate-scale training workloads. In 2026, 800G offers the best balance of performance, compatibility, and economic efficiency for most organizations.
Choose 1.6T if you manage a hyperscale AI factory or large distributed training cluster where bandwidth density is critical and budget allows for significant upfront investment. While more expensive and operationally complex, 1.6T provides a future-oriented platform for the most demanding AI workloads.
For many operators, a hybrid strategy is optimal: deploying 800G at the leaf layer, where cost sensitivity is highest, and reserving 1.6T for spine or core layers where bandwidth concentration delivers the greatest value. For deployment considerations, check our 800G cabling design guide for AI clusters to avoid common compatibility issues.By aligning transceiver choices with real workload demands rather than peak theoretical bandwidth, data centers can build scalable, cost-efficient AI networks that remain viable well beyond 2026.
