 English
English
What Is 800G InfiniBand?
800G InfiniBand (XDR) is a next-generation high-speed networking technology designed for AI and high-performance computing. It delivers 800 Gb/s bandwidth per port, ultra-low latency, and advanced features such as in-network computing (SHARP), enabling efficient scaling of GPU clusters to more than 10,000 nodes.
The Real Bottleneck in AI Infrastructure Is No Longer Compute
As AI models scale toward trillions of parameters, the primary constraint in large-scale training environments is no longer compute performance, but the efficiency of the network. In clusters with thousands of GPUs, the volume of east-west traffic grows exponentially, and communication-heavy operations such as AllReduce begin to dominate runtime.
When the network cannot keep up, GPUs spend more time waiting than computing. This leads to reduced utilization, longer training cycles, and significantly higher operational costs. As a result, modern AI infrastructure is shifting toward higher-bandwidth, lower-latency interconnects, with 800G InfiniBand emerging as a foundational technology for next-generation deployments.
Why 800G InfiniBand (XDR) Matters for AI
The transition from 400G to 800G InfiniBand represents more than a simple increase in bandwidth. It fundamentally reshapes how AI clusters are designed and how data flows between GPUs. With twice the bandwidth per link, the network can sustain significantly higher volumes of synchronization traffic, reducing congestion and improving overall system efficiency.
Latency improvements further enhance the performance of collective communication operations, which are central to distributed AI training. Technologies such as SHARP allow reduction tasks to be partially offloaded into the network fabric, minimizing compute overhead and enabling more efficient scaling.
As AI clusters expand beyond 1,000 GPUs, these advantages become increasingly critical. Without a high-performance interconnect, scaling efficiency quickly deteriorates. With 800G InfiniBand, however, it becomes possible to maintain near-linear performance even at very large scale.
800G InfiniBand Architecture for AI Clusters
A common reference design for modern AI infrastructure is a 144-node cluster built on a non-blocking spine-leaf topology. In this architecture, each server is equipped with next-generation XDR-capable SuperNICs, enabling extremely high bandwidth density per node while supporting both InfiniBand and Ethernet-based configurations.
The network fabric is organized into a two-layer structure, where leaf switches connect directly to servers and spine switches provide aggregation. This design assumes next-generation high-radix switches in the 144-port 800G class, allowing a balanced distribution of downlink and uplink connections and ensuring full bisection bandwidth.
Because each server connects through multiple independent paths, the architecture provides strong redundancy and predictable latency. This is essential for maintaining stable performance in large-scale AI workloads where even small delays can have a significant cumulative impact.
How to Scale AI Clusters to 10,000+ GPUs
To support large-scale expansion, the architecture adopts a modular design based on Scalable Units. Each unit consists of a fixed number of servers and GPUs, allowing the cluster to grow in predictable increments without requiring fundamental redesign.
In a typical configuration, one scalable unit includes 72 servers, corresponding to 576 GPUs when each server hosts eight GPUs. By combining multiple units, operators can scale from hundreds to thousands of GPUs while maintaining consistent network characteristics.
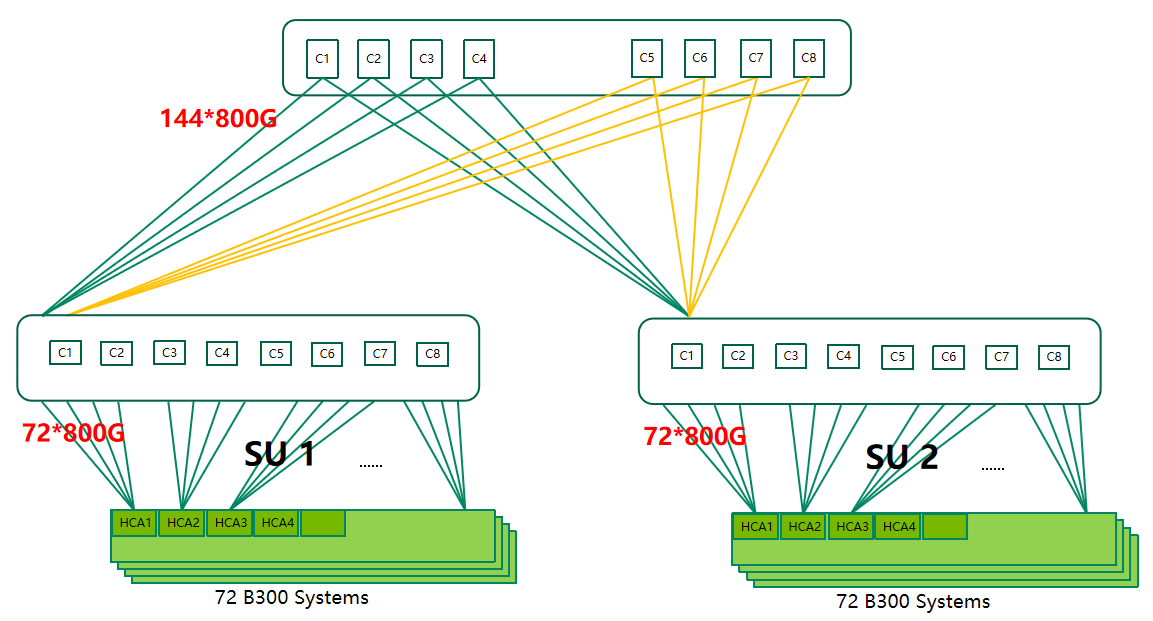
Extending this model further allows deployments to exceed 10,000 GPUs, reaching over 10,000 nodes within the same architectural framework. This modular approach
simplifies operations, improves fault isolation, and enables more efficient resource planning across the data center.
Why 800G InfiniBand Is Critical for Large AI Models
As models grow larger and more complex, communication overhead increases dramatically. The time required for synchronization between GPUs can quickly exceed computation time if the network is not sufficiently optimized. This imbalance becomes one of the primary barriers to efficient scaling.
800G InfiniBand addresses this challenge by significantly increasing available bandwidth while reducing latency. This enables faster synchronization, more efficient distributed training, and better overall utilization of compute resources. For organizations training large models, upgrading the network is not just an optimization—it is a necessity.
400G to 800G InfiniBand Upgrade Strategy
| Feature | 400G NDR | 800G XDR |
|---|---|---|
| Bandwidth | 400 Gb/s | 800 Gb/s |
| Interoperability | NDR ecosystem | Not directly interoperable at PHY level |
| Switch Type | QM9700 | XDR switches |
| NIC Support | ConnectX-7 | ConnectX-8 |
| Target Scale | ≤ 2K GPUs | 1K–10K+ GPUs |
Because 400G and 800G InfiniBand are not directly interoperable at the physical link level, upgrading requires a carefully planned migration strategy. A simple in-place upgrade is not feasible, and organizations must instead design a transition path that minimizes disruption while enabling gradual adoption of the new infrastructure.
Dual-Network Deployment for Seamless Migration
A practical and widely adopted approach is to deploy a dual-network architecture. In this model, a new 800G fabric is built alongside the existing 400G network, allowing current workloads to continue running without interruption.
During the transition phase, communication between the two environments can be achieved through gateway nodes or routing mechanisms. While this introduces additional complexity and may increase latency, proper tuning of communication frameworks such as NCCL or MPI can mitigate performance impact.
Workloads are then migrated in stages, starting with smaller tasks and gradually moving toward full-scale training. This phased strategy reduces risk while enabling a smooth and controlled transition to the new network.
800G Optical Transceivers and Cabling Options
The choice of interconnect plays a critical role in both performance and total cost of ownership. For short-distance connections within a rack, high-speed DAC cables offer a cost-effective and energy-efficient solution. However, for longer distances—especially between leaf and spine layers—optical transceivers become essential.
Modern 800G deployments typically rely on parallel optics such as DR4 and DR8 modules, often using MPO-based fiber connectivity. Selecting the right combination of copper and optical solutions allows operators to balance performance, scalability, and energy efficiency across the entire infrastructure.
Looking to deploy reliable 800G optical transceivers or optimize your cabling architecture? Choosing the right interconnect strategy can significantly reduce both power consumption and long-term operational costs.
InfiniBand vs RoCE for AI Data Centers
InfiniBand remains the dominant choice for ultra-large-scale AI training due to its ultra-low latency and advanced capabilities such as in-network computing. At the same time, RoCE-based Ethernet solutions are gaining traction in hyperscale environments, offering flexibility and broader ecosystem compatibility.
In many real-world deployments, organizations adopt a hybrid approach, using InfiniBand for performance-critical training workloads while leveraging Ethernet for storage and inference. This allows for a balanced strategy that aligns performance requirements with cost considerations.
Conclusion
The transition to 800G XDR InfiniBand marks a critical step in the evolution of AI infrastructure. By adopting a modular architecture, a non-blocking topology, and a phased migration strategy, organizations can scale efficiently to more than 10,000 GPUs without sacrificing performance.
As AI workloads continue to grow in scale and complexity, investing in a high-performance network is essential. The right interconnect strategy not only improves training efficiency but also maximizes the return on investment in GPU resources.
