In the era of AI, HPC, and cloud growth, networks have become critical to system performance. RoCEv2 (RDMA over Converged Ethernet v2) is now the standard for lossless Ethernet, offering ultra-low latency, high throughput, and minimal CPU overhead. As AI models scale to trillion-parameter levels, massive GPU clusters rely on RoCEv2 for efficient data exchange. While InfiniBand offers peak performance, RoCEv2 balances speed, cost, and ecosystem maturity, making it ideal for hyperscale and enterprise deployments. This guide covers RoCEv2 fundamentals, deployment strategies, optimization tips, and future trends for modern AI and data center networks.
What Is RDMA and Why It Matters
RDMA (Remote Direct Memory Access) allows data to be transferred directly from the memory of one host to another without involving the CPU, operating system kernel, or multiple memory copies. By bypassing the traditional TCP/IP stack, RDMA reduces end-to-end latency from tens of microseconds to sub-microsecond levels while freeing CPU resources for actual computation.
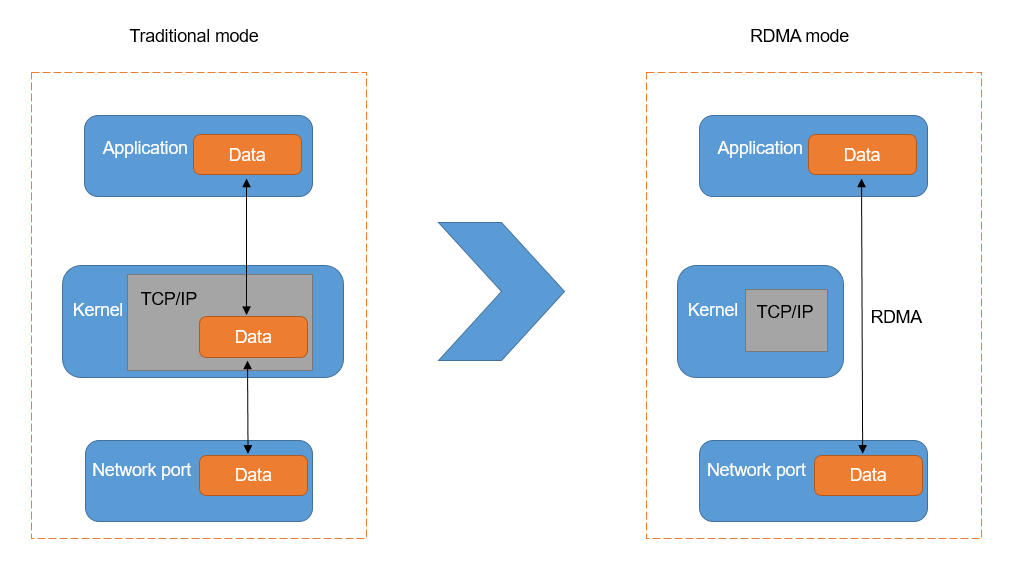
Figure 1: Compares the Traditional mode of data transfer, which requires the CPU to copy data through the OS Kernel (TCP/IP stack), with RDMA mode, which bypasses the kernel to allow direct data transfer between the Application and the Network port for significantly reduced latency.
Traditional TCP/IP networks suffer from several inherent limitations:
-
Frequent context switching and memory copying
-
High CPU utilization for protocol processing
-
Latency that does not scale well with increasing bandwidth
RDMA eliminates these bottlenecks through zero-copy transfers, kernel bypass, and hardware offloading. This makes RDMA particularly well-suited for AI workloads where GPUs must continuously exchange gigabytes of gradient data in real time.
RoCEv2: The Dominant RDMA Implementation
Today, there are three primary RDMA technologies:
-
InfiniBand (IB): A native RDMA solution based on specialized hardware, offering excellent performance but high cost and a relatively closed ecosystem.
-
iWARP: A TCP-based RDMA implementation with strong reliability, but higher protocol complexity and resource consumption.
-
RoCEv2: A UDP/IP-based RDMA solution that runs over standard Ethernet, combining routability, cost efficiency, and high performance.
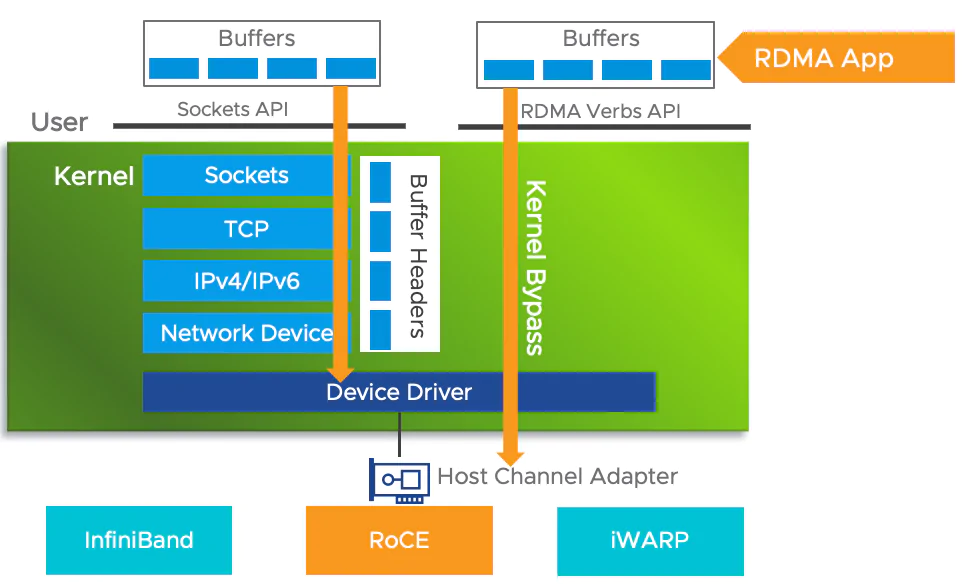
Figure 2: Architectural difference between a standard network stack, which processes data through multiple OS kernel layers, and RDMA which utilizes kernel bypass to allow an application to transfer data directly to the hardware for lower latency and higher efficiency.
RoCEv1 was limited to Layer 2 networks and could only operate within a single broadcast domain. RoCEv2, introduced in 2014, encapsulates RDMA packets in UDP/IP (destination port 4791), enabling Layer 3 routing and large-scale deployment across data center fabrics.
RoCEv2 has become the mainstream choice because it:
-
Works with existing Ethernet infrastructure (only RoCE capable NICs are required)
-
Offers significantly lower cost compared to InfiniBand
-
Delivers comparable performance in real world AI training workloads
Benchmark results show that for 7B-parameter BF16 model training, the performance gap between InfiniBand and RoCEv2 is often negligible. Hyperscalers such as Meta—deploying over 24,000 H100 GPUs for Llama-class training—have widely adopted RoCEv2 for large-scale AI clusters.
Core Technologies Behind RoCEv2 (PFC, ECN, DCQCN)
Lossless Ethernet as the Foundation
RDMA does not tolerate packet loss. Unlike TCP, RDMA protocols lack built-in retransmission mechanisms, making a lossless network mandatory for RoCEv2 deployments.
Key technologies that enable lossless Ethernet include:
-
PFC (Priority-based Flow Control): Prevents buffer overflow by pausing traffic on a per-priority basis without affecting other traffic classes.
-
ECN (Explicit Congestion Notification): Marks packets at congestion points, allowing endpoints to proactively reduce transmission rates.
-
DCQCN (Data Center Quantized Congestion Notification): Combines ECN marking with adaptive rate control to achieve high utilization and fair congestion management.
Advanced deployments increasingly leverage AI-assisted tuning, dynamically adjusting ECN thresholds and buffer policies based on real-time traffic patterns.
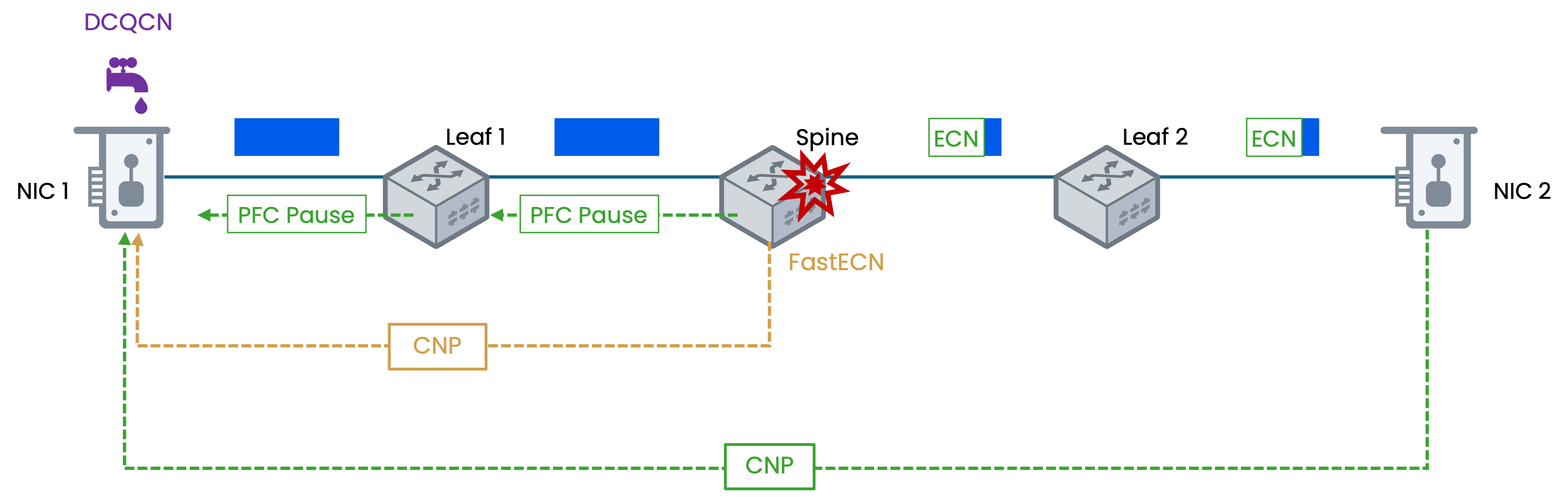
Figure 3: Mechanisms of DCQCN within an RDMA network, demonstrating how PFC Pause frames and CNP triggered by ECN/FastECN marking are used to manage traffic flow and prevent packet loss during network congestion.
Traffic and Congestion Management
Effective RoCEv2 networks require careful traffic engineering:
-
Assign priority queues for different traffic types.
-
Use scheduling algorithms such as WFQ (Weighted Fair Queuing) or WRR (Weighted Round Robin).
-
Apply differentiated QoS policies for AI workloads.
In GPU clusters, common communication patterns include:
Scaling POD (Point of Delivery) sizes helps reduce cross fabric traffic and minimizes congestion risks.
RoCEv2 vs. InfiniBand: Why Ethernet Keeps Winning
The formation of the Ultra Ethernet Consortium (UEC) in 2023—led by companies such as Meta, Intel, Cisco, and AMD—underscores Ethernet's long-term dominance. Ethernet port speeds (400G, 800G, and upcoming 1.6T) are advancing rapidly, supported by massive industry investment and an open ecosystem.
From a performance and architectural standpoint:
-
End-to-end latency is comparable to InfiniBand.
-
RoCE supports VXLAN, enabling cloud and multi-tenant deployments.
-
Migration costs are significantly lower, often requiring only NIC upgrades rather than a complete fabric replacement.
Optical Modules in RoCEv2 Networks
High-speed optical transceivers are a foundational component of RoCEv2-based AI fabrics. As link speeds scale from 400G to 800G and toward 1.6T, the performance characteristics of optical modules increasingly influence overall network efficiency, stability, and scalability.
In large GPU clusters, RoCEv2 traffic is continuous, bursty, and highly sensitive to latency variation and packet loss. This places stricter requirements on optical transceivers than traditional data center workloads.
Key Requirements for Optical Transceivers in RoCEv2 Fabrics
To support lossless Ethernet and RDMA traffic, optical modules must deliver:
-
Ultra-low latency and deterministic performance to avoid jitter amplification in AllReduce and collective operations.
-
Very low bit error rates (BER) under sustained high-throughput conditions.
-
Stable signal integrity across short-reach and medium-reach links inside AI data centers.
-
Consistent behavior under congestion control mechanisms such as PFC and ECN.
Unlike best-effort Ethernet traffic, even microbursts or transient errors at the optical layer can propagate upward and degrade GPU utilization efficiency.
Common Optical Module Types in AI RoCEv2 Networks
Typical optical transceivers deployed in RoCEv2-based GPU clusters include:
-
400G DR4/FR4 optical modules - widely used for current-generation AI clusters and leaf–spine fabrics.
-
800G DR8 or 2×400G FR4 modules - increasingly adopted for next-generation GPU fabrics and higher radix switches.
-
Future 1.6T OSFP optical modules - expected to enter mainstream deployment between 2025 and 2026.
Form factors such as QSFP-DD and OSFP are selected based on port density, power envelope, and thermal design constraints of switches and network interface cards (NICs).
Deployment Strategy: Multi-Rail for Extreme Scalability
Multi-rail architectures connect each server's GPUs to multiple independent leaf switches, dramatically improving scalability and reducing cross-POD congestion.
For example, with a 51.2T leaf switch:
-
A multi-rail design can support up to 512 × 400G NICs per POD, enabling thousands of GPUs.
-
A single-rail design may support only around 64 NICs, increasing cross-POD traffic by more than 8 times.
Combined with leaf-spine or three-tier topologies, multi-rail RoCEv2 networks can scale beyond 10,000 GPUs while maintaining 1:1 non-blocking bandwidth.
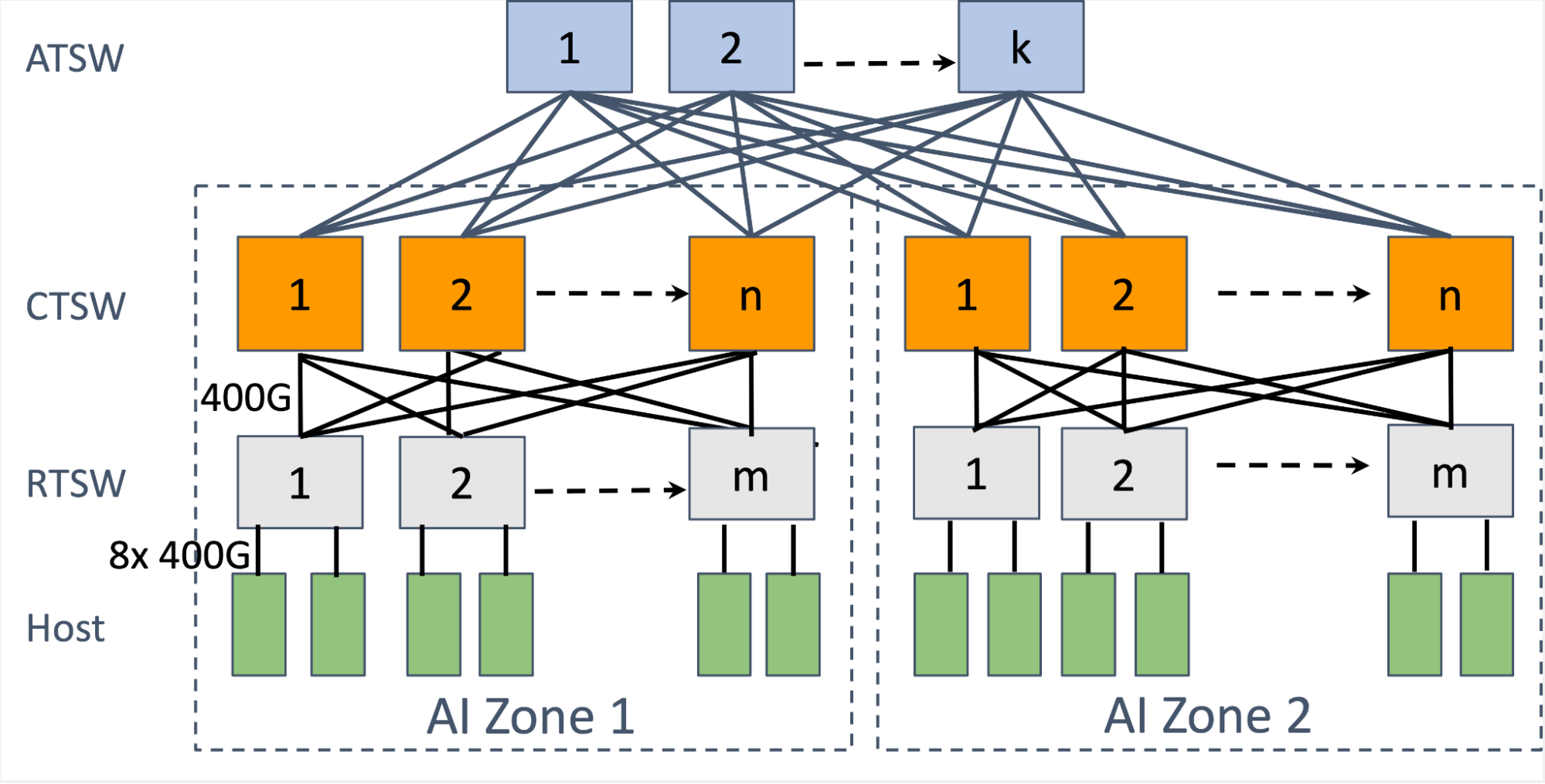
Figure 4: Multi-tier leaf-spine network architecture designed for high-performance AI clusters, featuring AI Zones interconnected by a hierarchy of switches (RTSW, CTSW, and ATSW) with high-bandwidth 400G links to ensure massive scalability and low-latency communication between hosts.
Future Trends (2026 and Beyond)
-
Continued evolution toward Ultra Ethernet with improved tail-latency performance.
-
Widespread adoption of 800G and 1.6T ports.
-
In-network computing for aggregation and reduction workloads.
-
Greater multi-vendor interoperability through open standards.
-
AI-native networks with predictive, self-optimizing traffic control.
As AI models continue to scale toward trillion-parameter levels, RoCEv2's routable and lossless design will remain central to next-generation AI infrastructure.
Building the Next-Generation AI Fabric with RoCEv2
RoCEv2 is more than a network upgrade—it is a foundational technology for scalable, efficient AI data centers. Delivering InfiniBand-class performance at a fraction of the cost, RoCEv2 enables organizations to build faster, larger, and more cost-effective GPU clusters.
By focusing on lossless network design, multi-rail architectures, high-speed optical modules, and intelligent automation, enterprises can confidently deploy RoCEv2 and prepare their infrastructure for the next wave of AI innovation.
 English
English