 English
English
InfiniBand network is a high-speed serial communication architecture specifically designed for high-performance computing and intelligent data interaction scenarios. Unlike Ethernet, it natively supports Remote Direct Memory Access (RDMA) technology and avoids the overhead of TCP/IP protocol stacks, making it a core infrastructure for breaking through data transmission bottlenecks in large-scale computing clusters. Currently, it is the mainstream intelligent computing network solution, with its market dominated by NVIDIA. It is widely used in building 10,000-card level large-scale GPU clusters. Relying on its outstanding performance and reliability, it has become a key support for AI data centers and provides underlying network guarantees for high-density data interaction scenarios such as large-scale AI training (e.g., GPT-series large model training) and scientific computing (e.g., quantum simulation, climate prediction).
Advantages of InfiniBand Network
In the technical architecture of AI data centers, the network plays a core role in data transportation. With its unique design, the InfiniBand network accurately meets the needs of high bandwidth, low latency, and high reliability in intelligent computing scenarios. Its specific advantages can be elaborated from three dimensions:
High Bandwidth
Through multi-link aggregation (such as 4x and 12x links) and continuously iterated rate standards (from the early 10Gb/s of SDR to the latest 800Gb/s of XDR), InfiniBand meets the requirement of large-volume parallel data transmission in 10,000-card GPU clusters. For example, when training 100-billion-parameter large models, GPUs need to exchange gradient data in real time. In a 1,000-card GPU cluster, even 400G Ethernet (with TCP/IP protocol overhead) can only achieve an actual available bandwidth of about 320Gb/s, while 400G InfiniBand (NDR standard) can reach an actual available bandwidth of over 380Gb/s, effectively preventing data transmission from becoming a bottleneck for computing efficiency.
Low Latency
It adopts Remote Direct Memory Access (RDMA) technology, which allows data to be directly transmitted from the memory of one device to that of another without going through CPU processing, thus greatly reducing the latency of data transmission. In AI training, low latency can shorten the waiting time for each iteration. Specifically, the latency of transmitting 1KB data via Ethernet is about 5-10μs, while InfiniBand with RDMA enabled can reduce the latency to 0.5-2μs. Especially in distributed training scenarios where multiple GPUs collaborate, this latency advantage can significantly improve the overall training efficiency—for instance, shortening the iteration time of a large model training task by 20%-30%.
High Reliability
Through the centralized management of the Subnet Manager (SM, the centralized manager of the InfiniBand subnet, responsible for route calculation and fault recovery), InfiniBand realizes the rapid detection and recovery of network faults. At the same time, it supports the partitioning strategy (Partitioning), which can divide the network into multiple independent subnets, preventing the failure of a single node from affecting the entire cluster and ensuring the continuity of AI tasks. This is crucial for large-scale computing clusters that need to run 24/7, such as AI inference clusters that provide real-time services for e-commerce recommendation systems.
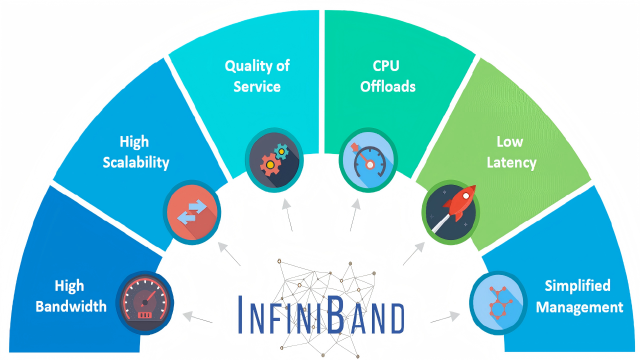
Figure 1: Advantages of InfiniBand
Core Components of InfiniBand Network
InfiniBand's performance advantages (high bandwidth, low latency) rely on the collaborative work of core components, and the evolution of port rates directly determines the performance upper limit of these components. The core components of the InfiniBand network mainly include the following four types:
Subnet Manager (SM)
It does not rely on traditional routing protocols but adopts a centralized management method. It is responsible for calculating and distributing the forwarding table of the entire network, and at the same time configuring the partitioning strategy, Quality of Service (QoS) and other characteristics within the subnet. Compared with the distributed routing of Ethernet, the centralized management of SM can reduce the time for route convergence after network faults, usually completing fault recovery within 10ms.
InfiniBand Network Adapter
It serves as the interface bridge for servers (or GPU nodes) to access the InfiniBand network, and its technical characteristics directly affect the interaction efficiency between nodes and the network. In addition to supporting RDMA technology to reduce CPU usage, mainstream network adapters (such as NVIDIA ConnectX series) also have multi-protocol compatibility, which can support both InfiniBand and Ethernet to adapt to hybrid network architectures. Some high-end network adapter models also support hardware-level traffic offloading, which can independently handle data encapsulation, decapsulation and other operations, further releasing the computing resources of the server. For example, the NVIDIA ConnectX-7 adapter can offload 90% of data processing tasks that would otherwise occupy the CPU, ensuring that the CPU focuses on core computing tasks.
InfiniBand Switch
It undertakes the task of data forwarding and needs to be matched with dedicated cables and optical modules to ensure the efficient flow of data in the network. Compared with traditional Ethernet switches, InfiniBand switches do not have the overhead of complex routing protocols. They only forward data based on the forwarding table distributed by the SM, resulting in lower forwarding latency. Moreover, they have the characteristic of high port density. For example, a single switch of the NVIDIA Quantum-2 series can provide dozens of ports with a bandwidth of 400Gb/s or above, which can efficiently connect multiple GPU nodes and simplify cluster cabling.
InfiniBand Cables and Optical Modules
They are the physical media connecting switches to network adapters and switches to switches. Their selection must strictly comply with the technical standards of InfiniBand, and they cannot be mixed with traditional Ethernet cables/optical modules. Cables need to support the unique signal transmission format of InfiniBand, and optical modules need to match the corresponding rate standards (such as NDR, XDR) and port types (such as OSFP). Otherwise, problems such as link failure or unstable transmission may occur. For example, using an Ethernet 800G SR8 optical module in an InfiniBand network will cause the link to fail to be established due to protocol incompatibility.
Evolution of InfiniBand Ports
With the development and iteration of technology, the network bandwidth of InfiniBand has been upgraded from the early SDR, DDR, QDR, FDR, EDR, HDR to NDR, XDR, and GDR. The evolution of port bandwidth is not only reflected in the increase of single-link rate but also in the further superposition of total bandwidth through the expansion of port width (such as 1x, 2x, 4x, 12x).
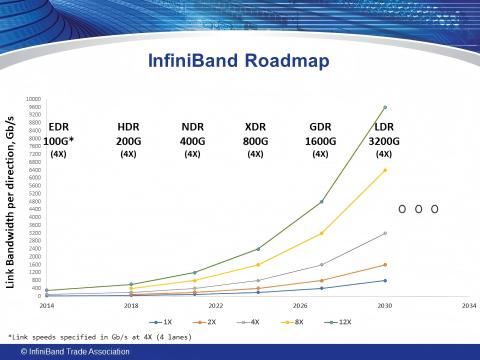
Figure 2: The IBTA's InfiniBand™ roadmap details 1x, 2x, 4x, and 12x port widths
It should be noted that the XDR rate standard mentioned in the industry usually corresponds to the actual deployment scenario of 4x port width. Specifically, under the XDR standard, the bandwidth of a 1x port is 200Gb/s, a 4x port can reach 800Gb/s (which is the common XDR application rate in current GPU clusters), and a 12x port can even achieve an ultra-high bandwidth of 2400Gb/s, which can meet the bandwidth needs of GPU clusters of different scales.
From the perspective of application scenarios:
Early SDR (10Gb/s) and DDR (20Gb/s) were mainly used in small and medium-sized high-performance computing scenarios, such as laboratory-level scientific computing clusters;
FDR (56Gb/s) and EDR (100Gb/s) were gradually adapted to large-scale data centers, supporting the construction of 100-card level GPU clusters;
HDR (200Gb/s) and NDR (400Gb/s) have become the mainstream choices for current AI training clusters, meeting the needs of 1,000-card level cluster construction;
XDR (800Gb/s) and GDR (1600Gb/s) are oriented to 10,000-card level ultra-large-scale clusters and provide bandwidth support for the training of higher-parameter large models (such as trillion-parameter models).
Hardware for InfiniBand Network Construction
The selection of the aforementioned hardware (switches, network adapters, optical modules, cables) must match the scale of the computing power cluster. The following is a detailed analysis of hardware selection for current mainstream InfiniBand network construction:
InfiniBand Switch
In the current construction of 1,000-card clusters, the deployment of InfiniBand networks usually requires a bandwidth of 400G or above. The QM9700 switch and QM9790 switch of the NVIDIA Quantum-2 series are the preferred models, and their specific parameters are as follows:
| Switch Series | NVIDIA SKU | Switch Model | Airflow Direction |
|---|---|---|---|
| QM9700 | 920-98210-00FN-0M0 | MQM9700-NS2F | Front (module side): P2C (Power-to-Connector, forward); Back (power side) |
| QM9700 | 920-98210-00RN-0M2 | MQM9700-NS2R | Front (connector side): C2P (Connector-to-Power, reverse); Back (power side) |
| QM9790 | 920-98210-00FN-000 | MQM9790-NS2F | Front (module side): P2C (forward); Back (power side) |
| QM9790 | 920-98210-00RN-000 | MQM9790-NS2R | Front (connector side): C2P (reverse); Back (power side) |
When selecting InfiniBand switch, the air inlet and outlet direction must be determined according to the deployment method of the computer room and the cabinet. For example, if the computer room adopts a front-cooling and rear-heating cabinet layout (cold air is supplied from the front of the cabinet, and hot air is exhausted from the rear), a switch with "Front P2C (forward) airflow" (such as MQM9700-NS2F) should be selected to ensure that cold air enters the device from the front and hot air is discharged from the rear, matching the computer room's heat dissipation system. If the direction is selected incorrectly, the heat dissipation efficiency of the equipment will decrease, and at the same time, it will bring great trouble to the cabling, affecting the overall network construction efficiency and stability. In addition, attention should also be paid to the redundancy design of the switch, such as whether it supports redundant power supplies and redundant fans, to improve the reliability of the equipment operation.

Figure 3: NVIDIA QM9700 switch
InfiniBand Network Adapter
Since the current InfiniBand networks generally require a bandwidth of 400G or above, the corresponding network adapters are mostly of the 400G OSFP type. Among them, the original NVIDIA ConnectX-7 400G OSFP network adapter is widely used.
The ConnectX-7 (400G OSFP) is a low-profile card with PCIe Gen5 x16. It supports InfiniBand and Ethernet protocols and has a transmission speed of up to 400Gb/s. It can provide intelligent, scalable, and feature-rich network solutions. It not only supports RDMA technology but also has features such as hardware-level encryption and traffic control, which can meet the workload needs of different scenarios such as traditional enterprises, artificial intelligence, scientific computing, and ultra-large-scale cloud data centers. In actual deployment, it is necessary to ensure that the network adapter is compatible with the PCIe slot version of the server motherboard (such as the PCIe Gen5 slot). If a PCIe Gen4 slot is used to match the ConnectX-7, the maximum transmission speed of the adapter will be limited to 200Gb/s, failing to fully release its performance due to interface mismatch.
Figure 4: NVIDIA ConnectX®-7 InfiniBand/VPI Adapter Card
InfiniBand Optical Module
It needs to support the rate standards of InfiniBand (such as NDR 400Gb/s, XDR 800Gb/s) and encoding methods (such as 256b/257b), and at the same time match the port types of switches and network adapters (for example, OSFP ports need to be matched with OSFP optical modules). For example, in an 800G XDR network, it is necessary to use an OSFP optical module that supports the XDR 800Gb/s rate to ensure the stability of optical signal transmission. If an Ethernet optical module (such as 800G SR8) is used, the link cannot be established due to protocol incompatibility.
When selecting an optical module, the choice between multimode and single-mode optical modules should be determined according to the distance of the computer room:
Multimode optical modules: Usually have a transmission distance of less than 50m and a lower cost, suitable for short-distance connections between cabinets (such as connections between nodes and Top-of-Rack Leaf switches).

Figure 5: AICPLIGHT 800GBASE 2xSR4/SR8 OSFP 50m InfiniBand NDR Optical Transceiver Module
Single-mode optical modules: The transmission distance can reach the kilometer level (for example, XDR 800Gb/s OSFP single-mode optical modules can cover 2km-40km depending on the laser type such as CWDM4 and LWDM), suitable for large-scale cluster networking across computer rooms and long distances, but their cost is relatively higher.
In addition, attention should also be paid to the power consumption of the optical module (generally, the power consumption of 400G InfiniBand optical modules should be controlled within 5W) to avoid increasing the heat dissipation pressure of the computer room due to excessive power consumption.
InfiniBand Cable
The InfiniBand network uses dedicated cables, which are different from traditional Ethernet cables and optical fibers. They mainly include DAC copper cables and AOC active optical cables, and their specific characteristics are as follows:
| Cable Type | Transmission Distance | Power Consumption (per meter) | Cost | Application Scenario |
|---|---|---|---|---|
| DAC (Direct Attach Copper) | ≤10 meters | 0.1-0.3W | Low | Short-distance connection within cabinets (e.g., between nodes and Top-of-Rack Leaf switches) |
| AOC (Active Optical Cable) | ≤100 meters | 0.5-1.0W | High | Medium-distance connection between cabinets (e.g., between Leaf switches and Spine switches) |
Select appropriate cables according to the transmission distance and cost budget: for short-distance transmission (within 10 meters) and limited budget, priority should be given to DAC copper cables; for long-distance transmission (10-100 meters) and high requirements for transmission stability, AOC active optical cables can be selected. It should be noted that the length and specifications of the cables must match the optical modules and switch ports. For example, a 400G network requires the selection of dedicated cables that support the 400G rate, and low-rate cables (such as 200G cables) cannot be used as substitutes—otherwise, the actual transmission rate will be limited to the cable's maximum rate.

Figure 6: AICPLIGHT 800G OSFP InfiniBand NDR Passive Direct Attach Copper Twinax Cable
InfiniBand: Computing Clusters & Optical Module Needs
The hardware selection of InfiniBand networks ultimately needs to match the demand for computing power clusters, especially the demand for optical modules, which is highly dependent on the cluster scale and architecture. Taking the mainstream Spine-Leaf network architecture as an example, the specific demand for optical modules is analyzed as follows:
According to the technical documentation provided by NVIDIA, in a cluster of 127 H100 servers (including 1016 GPUs), 32 Leaf switches and 16 Spine switches need to be configured (in the Spine-Leaf network architecture, Leaf switches connect to GPU nodes, and Spine switches connect different Leaf switches to realize cluster interconnection). Under the standard configuration without considering the Nvlink network and using multimode optical fibers, a total of 2421 800G OSFP optical modules are required, and the ratio of GPUs to 800G optical modules is 1:2.38. The calculation process of the number of optical modules is as follows:
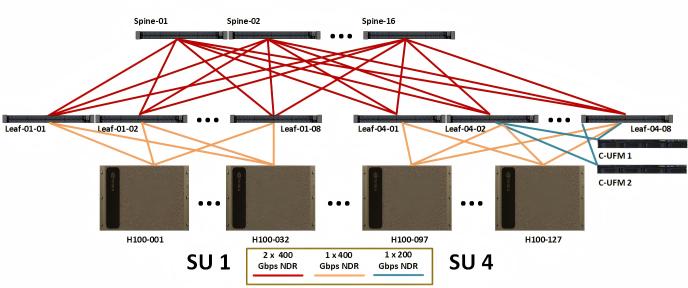
Figure 7: Compute InfiniBand fabric for full 127 node DGX SuperPOD
Connection between Leaf switches and GPU nodes: Each of the 1016 GPUs needs to be connected to a Leaf switch through a network adapter port, and each port requires 1 optical module. Therefore, 1016 optical modules are needed for this part;
Connection between Leaf switches and Spine switches: The Spine-Leaf architecture adopts a full interconnection mode. Each of the 32 Leaf switches needs to be connected to 16 Spine switches, and each connection requires 2 optical modules (one for the Leaf switch end and one for the Spine switch end). Therefore, the number of optical modules required for this part is 32 × 16 × 2 = 1024;
Redundancy configuration: To ensure network reliability, a 20% redundancy is usually reserved for optical modules. The total number of optical modules after redundancy is (1016 + 1024) × 1.2 ≈ 2448, which is close to the 2421 mentioned in the technical documentation (the difference is due to slight adjustments in the redundancy ratio or architecture details in actual deployment).
This data fully reflects the dependence of InfiniBand clusters on high-bandwidth optical modules: on the one hand, each GPU node needs to be connected to the Leaf switch through an optical module to ensure the data transmission of a single node; on the other hand, a large number of optical modules are also needed for the interconnection between Leaf and Spine switches to ensure the efficient flow of data within the cluster. As the scale of GPU clusters expands to the 10,000-card level, the demand for 800G and above optical modules will further increase, making them one of the core consumables for InfiniBand network construction.
Conclusion
Looking back at this article, InfiniBand has solved the data transmission bottleneck of AI clusters through three core capabilities: centralized management of Subnet Manager (high reliability), RDMA technology (low latency), and multi-link aggregation (high bandwidth). With these core advantages, the InfiniBand network has become the preferred network construction solution for large-scale GPU clusters in AI data centers. The entire process from component selection to architecture construction revolves around the core needs of intelligent computing scenarios. Whether it is the high-bandwidth support of the NVIDIA Quantum-2 series switches, the multi-protocol compatibility of the ConnectX-7 network cards, or the accurate matching of dedicated cables and optical modules, all provide guarantees for the stable operation of the InfiniBand network. The 1:2.38 ratio of GPUs to 800G optical modules also intuitively shows its dependence on high-bandwidth hardware.
In the future, as the parameter scale of AI models continues to expand and the number of GPU clusters increases, the InfiniBand network will evolve towards higher rates (such as GDR 1600Gb/s and above) and more flexible architectures (such as hybrid cloud intelligent computing networks). At the same time, it will further make breakthroughs in cost control and energy consumption optimization, continuing to provide underlying network support for the development of AI technology.
