The concept of the "AI factory" has rapidly emerged as a defining model for next-generation data centers. Unlike traditional enterprise or cloud data centers, AI factories are purpose-built to support large-scale AI training and inference workloads, such as large language models (LLMs), multimodal foundation models, and real-time generative AI services. These workloads generate unprecedented east–west traffic, placing extreme demands on data center networks in terms of bandwidth, latency, and scalability.
At the heart of this transformation lies the evolution of optical modules. As GPU clusters scale from hundreds to tens of thousands of accelerators, legacy 100G and 200G networks are no longer sufficient. The industry-wide transition toward 400G and 800G optical modules—especially within spine-leaf architectures—has become a foundational requirement for building efficient and future-ready AI factories.
This article examines why spine-leaf networks must evolve, how 400G and 800G optical modules fundamentally change network performance, and what best practices data center architects should follow when planning an upgrade.
Spine-Leaf Architecture: Foundation of the AI Factory Network
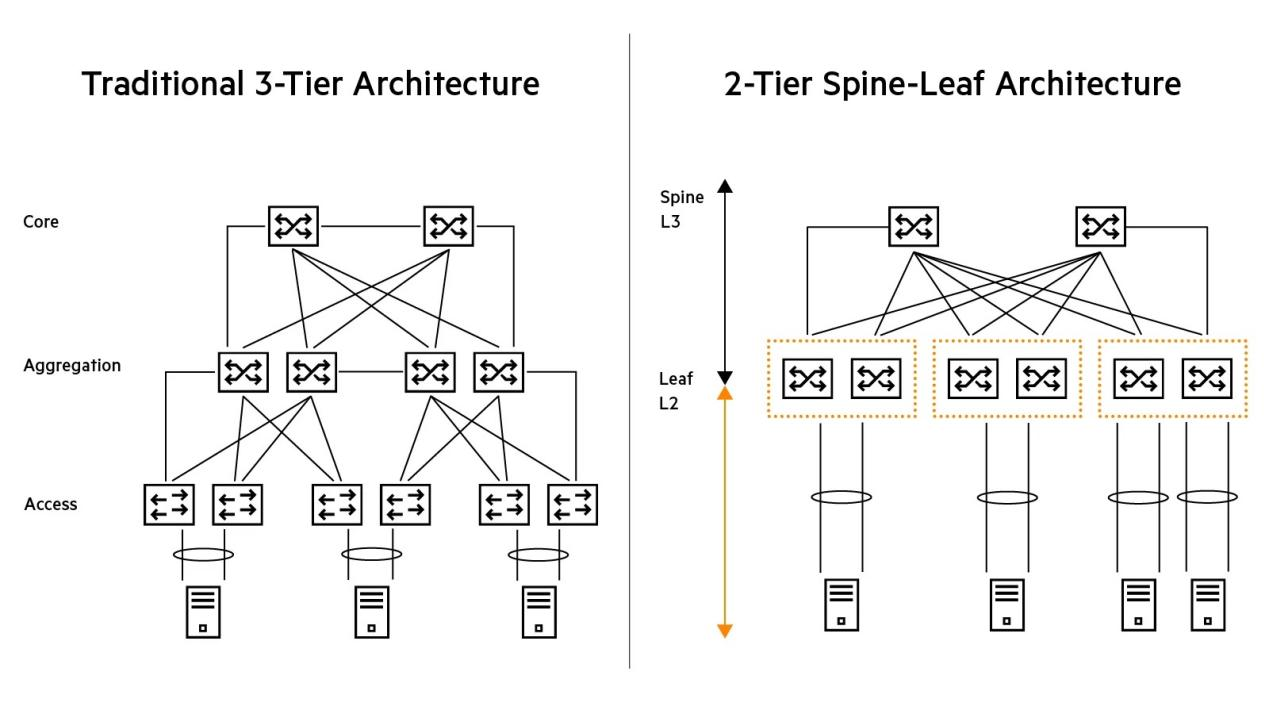
The spine-leaf architecture is a two-tier network topology designed to deliver predictable latency, high bandwidth, and linear scalability. In this design:
-
Leaf switches connect directly to servers, including GPU compute nodes, storage systems, and CPU clusters.
-
Spine switches interconnect all leaf switches, forming a full-mesh fabric that ensures any leaf can reach another leaf in a consistent number of hops—typically one.
Compared with traditional three-tier (core - aggregation - access) architectures, spine-leaf networks eliminate oversubscription bottlenecks and reduce latency variation, both of which are critical for distributed AI training.
Figure 1: Traditional 3-tier architecture (core-aggregation-access) vs. 2-tier spine-leaf architecture (Source: HPE)
However, many early spine-leaf deployments were built around 100G or 200G optical modules, which were originally designed for cloud computing and general enterprise workloads. While adequate for web services and virtualization, these legacy links quickly become constraints in AI environments, where synchronized GPU communication (e.g., all-reduce operations) dominates network traffic.
Limitations of 100G and 200G Networks in AI Workloads
AI training workloads are fundamentally different from traditional applications. During distributed training, GPUs continuously exchange gradients and model parameters, often generating terabits per second of east-west traffic across the fabric.
In practice, 100G and 200G networks face several challenges:
Bandwidth constraints
With limited per-port bandwidth, leaf switches can only support a relatively small number of high-performance GPUs before uplinks become oversubscribed. This forces architects to deploy more switches, increasing network complexity and cost.
Latency sensitivity
While the absolute latency difference between generations of optical modules is measured in nanoseconds, AI training is highly sensitive to cumulative delay and jitter. Network inefficiencies can extend training cycles from days to weeks at scale.
Power and cooling inefficiency
Although 100G and 200G modules consume less absolute power than higher-speed modules, their power per transmitted bit is significantly worse. As AI factories scale, inefficient watts-per-Gbps ratios translate directly into higher operational expenditure.
These limitations make it clear that incremental upgrades are no longer sufficient. A step-change in network capacity is required.
How 400G Optical Modules Enable the Next AI Scaling Phase
400G optical modules represent the first major inflection point for AI-driven data center networking. By consolidating bandwidth into higher-speed ports, 400G dramatically improves fabric efficiency.
Key benefits include:
-
4× bandwidth per port compared with 100G
-
Improved watts-per-Gbps efficiency, reducing energy cost per unit of traffic
-
Reduced switch count, simplifying network topology and cabling
-
Better support for GPU-heavy leaf switches, especially for medium-scale clusters
In real-world deployments, 400G enables AI factories with several hundred to a few thousand GPUs to scale efficiently without excessive network complexity. For inference-dominated workloads or mixed training and inference clusters, 400G remains a highly cost-effective and widely adopted option.
800G Optical Modules: Scaling AI Factories to Hyperscale
As AI models continue to grow in size and complexity, leading hyperscalers are moving rapidly toward
800G optical modules, particularly in spine layers.
800G provides:
-
Double the bandwidth of 400G, enabling denser GPU clusters
-
Lower effective latency through reduced congestion
-
Fewer fibers and transceivers per terabit, improving physical-layer efficiency
-
Stronger future-proofing for next-generation AI models
By using 800G links in the spine, AI factories can interconnect thousands or even tens of thousands of GPUs with fewer hops, fewer ports, and lower operational overhead. This approach is increasingly common in cutting-edge AI training environments where network performance directly determines time-to-model.
Best Practices: Deploying 400G and 800G in Spine-Leaf Networks
A successful upgrade strategy typically involves a hybrid approach rather than a one-size-fits-all deployment.
Spine layer recommendations
Spine switches carry aggregated traffic from all leaf switches, making them the most bandwidth-intensive part of the network. Deploying 800G optical modules in the spine maximizes fabric capacity, reduces oversubscription risk, and delays the need for future upgrades.
Leaf layer recommendations
Leaf switches should be selected based on GPU density and workload type.
400G is well suited for inference clusters and moderate-scale training environments.
800G becomes advantageous for high-density GPU nodes and large-scale distributed training.
Compatibility and validation
Ensure optical modules are fully compatible with switch ASICs, cabling infrastructure, and thermal design limits. Interoperability testing is critical to avoid hidden performance bottlenecks in production environments.
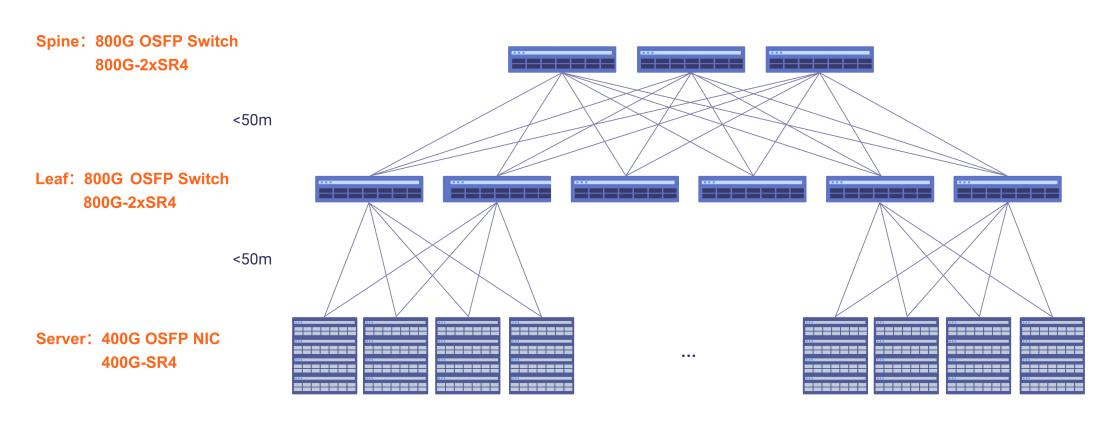
Figure 2: A spine-leaf data center network topology using 800G OSFP optical links at the spine and leaf layers, with 400G OSFP NIC connections to servers. The architecture illustrates high-bandwidth, low-latency interconnects designed for scalable AI and GPU cluster deployments.
Conclusion
The evolution from 100G and 200G to 400G and 800G optical modules is not a routine network upgrade—it is a strategic enabler for AI factories. High-speed optical interconnects determine how efficiently GPUs can communicate, how fast models can be trained, and how cost-effectively AI infrastructure can scale.
By carefully aligning optical module selection with spine-leaf architecture design, workload characteristics, and long-term growth plans, data center operators can build networks that are not only ready for today's AI demands but also prepared for the next generation of AI innovation.
In the era of AI factories, optical modules are no longer passive components—they are a core driver of performance, efficiency, and competitive advantage.
 English
English