As large language models (LLMs), multimodal AI, and high-performance computing (HPC) workloads continue to scale, data center networks are undergoing a fundamental transition. While GPU compute capability has increased rapidly, network efficiency has emerged as one of the primary constraints on overall system utilization.
Modern AI training is no longer limited purely by compute throughput. Instead, the ability to move massive volumes of data efficiently, predictably, and at low latency between GPUs has become a decisive factor in training time, cluster utilization, and infrastructure cost.
If dual-port 2×400GbE already provides 800Gb/s of aggregate bandwidth on paper, why does network communication still become a bottleneck in large-scale AI training?
Against this backdrop, NVIDIA ConnectX-9 SuperNIC introduces a significant architectural shift: native single-port 800GbE, replacing the widely deployed dual-port 2×400GbE design used in previous generations such as ConnectX-8. Although both approaches offer the same theoretical aggregate bandwidth, their real-world behavior under AI and HPC workloads differs in critical ways.
This article explores why that difference matters, how 1×800G changes network behavior for AI and HPC clusters, and how data center architects should evaluate the trade-offs between these two designs.
The Legacy Model: 2×400GbE Architecture
How 2×400G Works in Practice
In a 2×400GbE configuration, a single network interface card exposes two independent 400Gb/s Ethernet ports. To achieve the full 800Gb/s aggregate bandwidth, traffic must be distributed across both links.
In production networks, this distribution is typically achieved through:
Both mechanisms rely on hashing traffic flows—commonly using 5-tuple parameters such as source and destination IP addresses and transport-layer ports—to determine which physical link carries each flow.
This approach is well understood and effective for many traditional workloads, but it has important implications for traffic patterns dominated by large, long-lived flows.
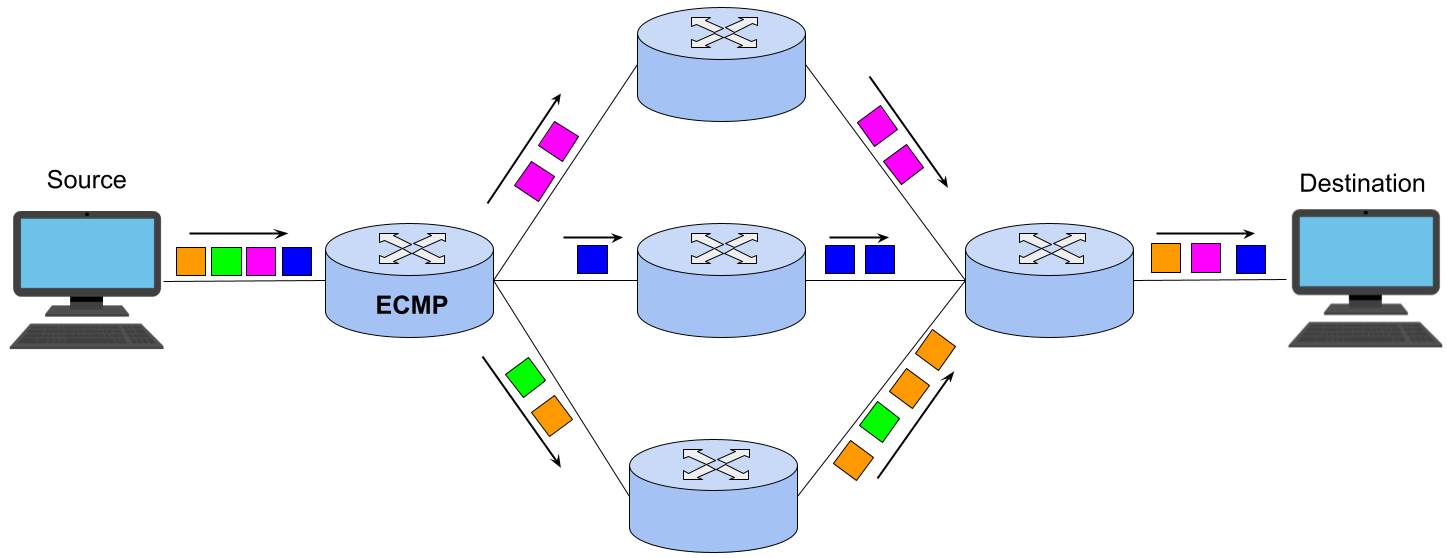
Figure 1: Understanding ECMP routing
Strengths of the Dual-Port Design
The 2×400G model offers several well-established advantages:
-
Native physical redundancy: Each port can connect to a separate switch or even an independent network plane.
-
Excellent performance for mixed workloads: Large numbers of small, short-lived flows are naturally balanced by ECMP hashing.
-
Mature ecosystem: 400G optics, switches, and cabling are widely deployed and operationally well understood.
For cloud platforms, virtualization environments, and general-purpose data centers where availability and workload diversity are critical, 2×400G remains a robust and proven architecture.
Why 2×400G Becomes a Bottleneck for AI Training
AI Traffic Is Dominated by Elephant Flows
AI training workloads behave very differently from traditional enterprise or cloud traffic. Collective communication patterns such as All-Reduce, All-Gather, and All-to-All generate large, sustained data transfers between GPUs.
Under conventional ECMP or LACP hashing mechanisms without flowlet-based load balancing or packet spraying, these elephant flows typically exhibit the following behavior :
-
A single large flow is often hashed entirely onto one 400Gb/s link.
-
The second 400Gb/s link may remain partially or completely underutilized.
-
The effective bandwidth for that flow is capped at 400Gb/s, despite 800Gb/s being available in theory.
The result is uneven link utilization and reduced communication efficiency—an issue that becomes increasingly visible as cluster size grows.
Impact on GPU Utilization
When GPUs wait on network communication to complete, compute resources stall. Even modest inefficiencies in bandwidth utilization can compound across thousands of GPUs, leading to:
Advanced techniques such as customized ECMP hashing, flow-aware scheduling, or application-level sharding can mitigate some of these effects, but they introduce operational complexity and do not fully eliminate the fundamental limitations of aggregating bandwidth across multiple physical links.
The New Model: Native 1×800GbE with ConnectX-9
What Changes with Single-Port 800G
ConnectX-9 introduces a true single-port 800GbE interface, presenting the full bandwidth as one logical Ethernet link rather than two aggregated links.
Figure 2: NVIDIA ConnectX-9 SuperNIC
From the NIC and host perspectives :
-
Bandwidth utilization no longer depends on cross-link hashing at the NIC interface.
-
A single large flow can effectively consume the available bandwidth.
-
Throughput becomes more predictable for long-lived transfers.
ECMP remains relevant at the fabric level for multi-path routing, but it is no longer required to aggregate bandwidth at the NIC itself. This distinction is especially important for AI and HPC workloads, where sustained throughput and consistency matter more than fine-grained flow-level load balancing.
Alignment with Modern Server Architectures
Single-port 800G aligns naturally with modern server and accelerator platforms:
-
PCIe Gen5 x16 provides sufficient bandwidth headroom in contemporary server designs to support 800GbE without contention.
-
Improved support for GPUDirect RDMA reduces data movement overhead between GPUs and the NIC.
-
Better utilization of collective communication optimizations such as SHARP, improves scaling efficiency.
Together, these factors help reduce communication bottlenecks inside tightly coupled GPU clusters.
Deployment Considerations for 800G Ethernet
Optics and Cabling
In real-world deployments, native 800G Ethernet typically relies on:
-
QSFP-DD 800G single-mode optics, such as DR8 or FR4.
-
OS2 single-mode fiber, enabling longer reach and more flexible data center layouts.
While multimode options like 800G SR8 exist, they are generally limited to very short distances and are less common in large-scale AI fabrics.
Switch Infrastructure Requirements
To fully realize the benefits of single-port 800G, the entire network path must support 800GbE:
-
Switch ASICs must provide native 800G ports.
-
Oversubscription at aggregation layers should be carefully managed.
-
Power and thermal characteristics must be considered at high port densities.
Without end-to-end 800G support, the advantages of a single-port architecture may be partially diminished.
2×400G vs 1×800G: Architectural Comparison
| Dimension |
2×400GbE |
1×800GbE |
| Aggregate bandwidth |
800Gb/s |
800Gb/s |
| Peak bandwidth per flow |
400Gb/s |
Up to 800Gb/s |
| Dependence on ECMP for NIC bandwidth utilization |
High |
Low |
| Elephant flow efficiency |
Medium |
High |
| Native link-level redundancy |
Strong |
Limited |
| AI training suitability |
Conditional |
Excellent |
Redundancy and Multi-Plane Network Design
Advantages of 2×400G in Multi-Plane Fabrics
Dual-port NICs integrate naturally into multi-plane network architectures. By connecting each port to a separate fabric, operators can achieve:
For environments prioritizing per-port fault tolerance over peak per-flow throughput, this remains a compelling advantage.
Redundancy Strategies with 1×800G
A single 800G port introduces a potential single point of failure at the link level. Redundancy can still be achieved through:
While effective, these approaches increase cost and design complexity. As a result, 1×800G is most attractive in scenarios where maximum per-node bandwidth outweighs per-port redundancy, such as tightly coupled AI training fabrics or high-density spine interconnects.
Choosing the Right Architecture
Rather than viewing 2×400G and 1×800G as direct replacements, it is more accurate to treat them as complementary design options:
-
2×400G excels in cloud platforms, mixed workloads, and environments requiring strong native redundancy.
-
1×800G excels in AI training and HPC clusters dominated by large, sustained data transfers.
At equivalent total bandwidth, 1×800G can also reduce the number of optics, fibers, and switch ports required, simplifying cabling and potentially improving power efficiency. These benefits must be weighed against hardware cost, redundancy strategy, and long-term scaling goals.
Final Thoughts
The transition from 2×400G to native 1×800G Ethernet reflects a broader shift in data center networking: from generalized, availability-first designs toward bandwidth-optimized fabrics tailored for AI workloads.
NVIDIA ConnectX-9 does not render dual-port architectures obsolete. Instead, it expands the design space available to network architects, enabling fabrics that more closely align with the communication patterns of modern AI and HPC systems.
Selecting the optimal approach ultimately depends on workload characteristics, failure tolerance, and the long-term evolution of the data center network.
 English
English