Introduction
High-performance computing scenarios such as AI training and large-scale data processing impose extreme demands on network link bandwidth, latency, and collaboration capabilities, creating a core bottleneck that constrains system performance. The NVIDIA ConnectX-8 series Network Interface Cards (NICs) serve as a critical solution to these bottlenecks, leveraging an advanced hardware architecture and deeply optimized collaboration capabilities.
1. NVIDIA ConnectX-8 Series: Accelerating Next-Gen AI & HPC
1.1 ConnectX-8 SuperNIC Architecture
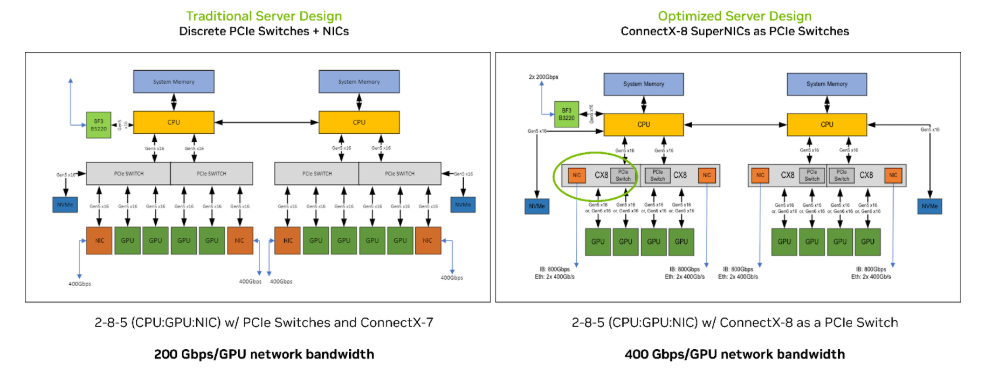
The ConnectX-8 SuperNIC utilizes an innovative integrated architecture, featuring a built-in PCIe Gen6 switch combined with ultra-high-speed networking capabilities. It enables efficient inter-GPU and GPU-to-NIC communication without the need for discrete PCIe switches, significantly simplifying system design and improving energy efficiency. It employs a flattened network topology to achieve XDR performance and includes a dedicated "Data Direct" sideband DMA engine to build direct data paths to the GPU. This engine enables access to data buffers via MKey authorization, catering to the multi-PCIe data path requirements of NUMA systems. Furthermore, it integrates advanced congestion control mechanisms and in-network computing capabilities, supporting QoS and multi-protocol encapsulation offloading to provide performance isolation and low-latency guarantees for large-scale AI clusters.
1.2 NVIDIA CX8S
As a signature model in the ConnectX-8 series, the NVIDIA CX8S is optimized for high-performance AI and data center scenarios. Adopting a half-height, half-length (HHHL) form factor, it complies with mainstream standards like OCP 3.0, offering excellent compatibility and deployment flexibility. This model retains the core PCIe Gen6 x16 interface design and supports Socket Direct™ 16-lane expansion, enabling seamless integration with NVIDIA Server GPUs to build collaborative architectures. At the hardware level, it features reinforced data encryption engines with full support for hardware offloading of encryption protocols such as TLS and IPSec. Additionally, it optimizes power consumption, providing high-bandwidth transmission while reducing operational costs, making it particularly suitable for GPU cluster deployments with stringent security and energy efficiency requirements.
1.3 Core Performance Metrics
The ConnectX-8 series delivers industry-leading core performance metrics. At the network layer, it supports 800Gb/s InfiniBand XDR and dual 400GbE Ethernet speeds, with single ports enabling high-speed data transmission via PAM4 modulation. Regarding interface layer, it is equipped with 48 lanes of PCIe Gen6, reaching transmission rates of 64GT/s while remaining backward compatible with previous PCIe standards to fully unleash the I/O potential of next-generation Server GPUs. In terms of collaborative performance, GPU-Direct RDMA technology enables direct data transfers, resulting in up to a 2x improvement in NCCL All-to-All performance, a 60% reduction in AI training step time, and near-zero tail latency. Furthermore, it possesses the hardware-level encryption and precise timing control capabilities typical of the 900-9x81 series, further ensuring data transmission security and stability.
2. ConnectX-8 and NVIDIA Server GPUs Co-Optimization
2.1 GPU-NIC Direct-Connect Architecture
The ConnectX-8 introduces a GPU-NIC direct-connect architecture by integrating a PCIe Gen6 switch, eliminating the need for traditional discrete PCIe switches. This design consolidates inter-GPU and GPU-to-NIC communication into a single device, significantly simplifying system topology and removing transmission bottlenecks.
Key features:
-
Socket Direct™ Technology: Enables direct PCIe access across multiple CPU sockets via dedicated MCIO cabling, granting each GPU 50GB/s of dedicated bandwidth. This avoids network traffic crossing the processor bus.
-
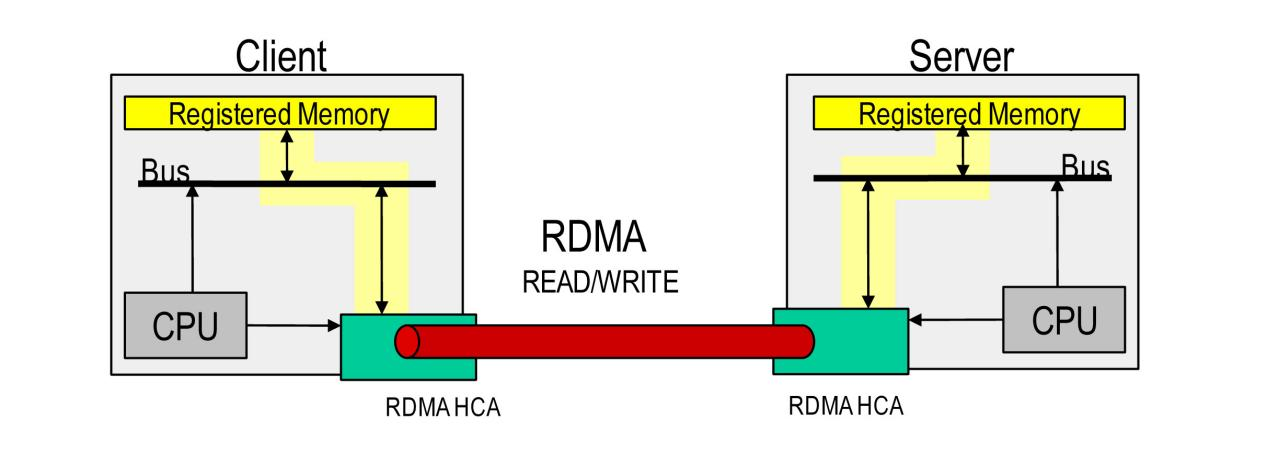
GPU-Direct RDMA: Establishes a direct data path by leveraging Data Direct side-channel DMA engines to access GPU buffers directly, bypassing CPU intervention. This reduces data transfer latency by 80% and cuts CPU utilization by 50%, fully unleashes computational resources for NVIDIA Server GPUs.
2.2 Multi-GPU Cluster Performance Scaling
In multi-GPU cluster deployments, the synergy between ConnectX-8 and NVIDIA Server GPUs delivers performance doubling, primarily driven by deep optimization of NCCL collective communications.
Key features:
-
Flat Topology & Direct Forwarding: The direct-connect architecture allows network-level forwarding between GPUs, boosting NCCL All-to-All performance by up to 2× and reducing AI training step time by 60%.
-
Scalability for Large Clusters: With 48 lanes of PCIe Gen6 bandwidth, ConnectX-8 provides sufficient I/O for 8+ GPU clusters, ensuring linear performance scaling via advanced congestion control and SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) enhancements.
-
Security & Throughput: The CX8S model offloads hardware encryption, ensuring secure multi-node data transfers while maintaining high throughput and performance isolation for trillion-parameter AI workloads.
3. ConnectX-8 Performance in Three Typical Application Scenarios
3.1 AI Training & Inference
-
800Gb/s Ultra-High Bandwidth: Enables low-latency data exchange between NVIDIA Server GPUs via GPU-Direct RDMA, bypassing CPU bottlenecks.
-
Optimized NCCL Communication: Boosts collective communication throughput for large-scale model training, improving multi-GPU synchronization efficiency.
-
QoS for Inference Stability: Ensures stability in real-time AI inference workloads.
-
CX8S Hardware Encryption: Meets security requirements for sensitive industries (e.g., healthcare, finance) without compromising performance.
3.2 Large-Scale Cloud Data Centers
-
High Scalability & Efficiency: Supports 2×400GbE Ethernet and PCIe Gen6 interface expansion, enabling 50% higher port density and 30% lower deployment costs with flattened topology.
-
Virtualization Optimization:
a.SR-IOV ensures per-VM bandwidth isolation with consistent low latency.
b.Half-height, half-length (HHHL) CX8S model fits high-density servers, reducing power consumption by 25% per port for greener operations.
c.Cloud-Native Adaptability: Ideal for hyper-scale cloud providers needing elastic expansion while maintaining energy efficiency.
3.3 High-Performance Computing (HPC)
-
InfiniBand XDR 800Gb/s + SHARP Acceleration: Reduces inter-node latency by 40%+, enhancing parallel computation efficiency.
-
Heterogeneous Computing Support: Seamless data flow between NVIDIA GPUs and CPUs, eliminating network bottlenecks in mixed workloads (e.g., CFD, genomics).
 English
English