Introduction
A 2025 incident review by a leading cloud provider revealed that a mere 3-second microburst traffic spike caused a 0.8% packet loss in financial transaction links, resulting in a direct loss of $27 million. The root cause was not insufficient bandwidth but the default static buffer partitioning policy of ToR switches.
This case reveals a harsh reality: in the era of 25G/100G networks, buffer management has become the decisive factor for network reliability. Modern switch chip architectures are undergoing a paradigm shift—from fixed partitions to dynamic shared pools, from passive packet drops to active queue management (AQM), and from single-queue QoS to multidimensional traffic shaping.
1. In-Depth Analysis of Buffer Architectures
1.1 Shared vs. Dedicated Buffers
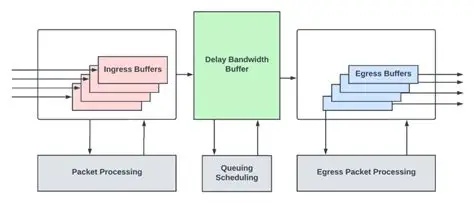
A switch's buffer architecture determines its fundamental ability to handle traffic bursts. Traditional designs allocate dedicated buffers to each port, which leads to wasted resources when traffic loads are uneven across ports. In contrast, modern shared buffer architectures centralize buffer resources for dynamic allocation and efficient utilization.
Take Broadcom's Trident4 chip as an example: its 64MB shared cache pool employs dynamic partitioning algorithms to adapt flexibly based on real-time traffic patterns. This approach outperforms even 256MB static dedicated buffers in practice. Beyond improving utilization, shared buffers simplify network planning, making them the preferred solution for high-burst scenarios.
1.2 Queue Management Algorithms
When buffer resources near exhaustion, intelligent packet discard mechanisms are critical to preventing network collapse. Early solutions like Random Early Detection (RED) relied on random drops to mitigate congestion but suffered from complex configurations and insensitivity to traffic diversity.
As networks grew more complex, advanced AQM algorithms emerged. CoDel excels in data center environments by precisely controlling queue latency, stabilizing jitter below 5ms for real-time applications. Meanwhile, the Proportional Integral controller Enhanced (PIE) algorithm, with its hardware-optimized implementation, delivers lower latency and higher throughput, becoming the mainstream choice for modern switches.
1.3 Burst Absorption Capability
Microbursts are stealthy culprits behind transient congestion. Triggered by protocols, traffic shaping, or device behaviors, they last mere milliseconds but pack extreme intensity. Traditional port-rate-based monitoring struggles to detect such ephemeral events.
Modern tools like NetFlow and sFlow analyze traffic patterns at millisecond granularity, enabling precise microburst identification. By integrating these analytics with switch buffer monitoring, engineers can proactively predict potential congestion points and dynamically adjust buffering strategies.
2. Buffer Optimization Strategies and Practical Techniques
2.1 Optimal Buffer Depth
There is no universal "best" buffer size—it requires scientific tuning based on network topology, traffic patterns, and business requirements. A rule of thumb is that the buffer depth should at least accommodate the data volume transmitted during the maximum round-trip time (RTT) to avoid retransmissions and congestion caused by acknowledgment delays.
Within data centers, where RTT is extremely low, smaller cache depths are typically used. Conversely, in wide area networks (WAN) or cross-data center links with longer RTT, larger cache depths are required to accommodate more packets.
2.2 Triple-Layered Defense Against Packet Drops
Minimizing packet drops is the holy grail of buffer management. A three-tiered approach ensures graceful degradation under congestion:
-
Traffic Shaping (First Line): Smooths bursts using token/leaky bucket algorithms (e.g., 1Gbps interface shaped to 800Mbps to absorb microbursts).
-
Priority Queuing (Second Line): Guarantees bandwidth for critical traffic (e.g., VoIP/Database marked as DSCP EF/CS6 and mapped to high-priority queues).
-
Active Queue Management (AQM) (Third Line): Proactively drops/marks packets (via ECN) when queues near capacity. Modern AQM algorithms like FQ-CoDel or PIE outperform legacy RED by adapting to dynamic traffic.
2.3 QoS Implementation in Switches
QoS transforms raw buffers into intelligent traffic handlers. The workflow involves:
-
Classification: Identifies traffic types (e.g., using ACLs, DSCP, or VLAN tags).
-
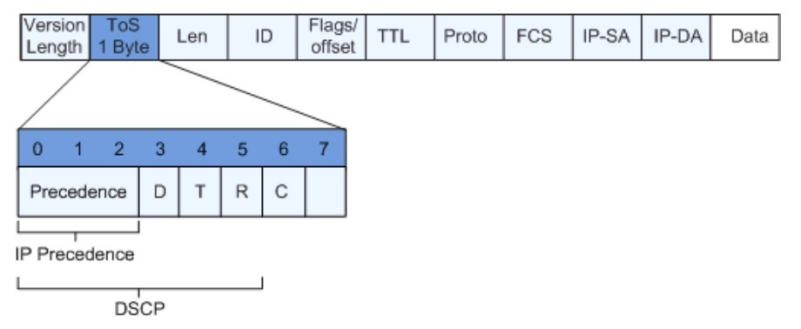
Marking: Assigns priority labels (e.g., setting IP Precedence for video streams).
-
Policy Mapping: Directs marked traffic to designated queues/schedulers (e.g., strict-priority for latency-sensitive flows).
-
Scheduling: Dictates transmission order (e.g., Weighted Fair Queuing + Deficit Round Robin).
Taking Cisco's BufferBoost technology as an example, it achieves multi-dimensional traffic shaping and QoS policies through hardware acceleration. This technology dynamically adjusts buffer allocation based on real-time network conditions, providing differentiated quality of service guarantees for traffic of varying priorities.
3. Future Trends and Challenges
The advent of 400G Ethernet has pushed packet processing speeds to hundreds of millions per second, imposing unprecedented demands on buffer capacity, bandwidth, and access latency. Traditional buffer architectures face bandwidth bottlenecks, necessitating innovations like buffer bypassing (e.g., Intel's DCA) and distributed buffer pools (e.g., disaggregated switch models) to meet 400G performance targets.
Simultaneously, the global focus on carbon neutrality has made energy efficiency a critical design constraint. While larger buffers improve performance, they also increase power consumption. Consequently, green caching has emerged as a new research direction. It aims to minimize cache energy consumption through intelligent algorithms and hardware optimization while maintaining performance, thereby building sustainable network infrastructure.
 English
English