 English
English
Against the backdrop of deep integration between artificial intelligence (AI) and big data technologies, smart computing centers have become the core infrastructure driving global digital transformation. As large AI models surpass one trillion parameters and data processing volumes grow exponentially, traditional network architectures struggle with bandwidth bottlenecks, excessive latency, and unregulated energy consumption, making them unable to support high-performance workloads like AI training and supercomputing.
In this context, the 51.2T RoCE switch, with its core advantages of ultra-high bandwidth, ultra-low latency, and high cost-effectiveness, has emerged as a key solution for network upgrades in smart computing centers. It not only builds a stable, high-performance network foundation for AIGC clusters and core switching scenarios in data centers but also helps enterprises quickly adapt to business requirements. For example, distributed training of trillion-parameter AI models requires terabytes of data interaction per iteration. Traditional 25.6T switches need multi-device cascading (increasing latency by 15%-20%), while a single 51.2T RoCE switch can directly support 1,000+ GPU cluster interconnection, aligning with the real-time data transmission needs of large models.
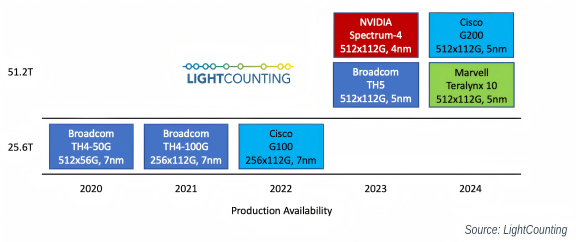
Figure 1: This timeline shows the production availability of 51.2T switch ASICs from major vendors (2020-2024), highlighting Broadcom's and NVIDIA's first-mover advantage in the 51.2T chip market (source: LightCounting).
I.Mainstream 51.2T Switch Chip Solutions in the Market
Currently, 51.2T switch chip solutions from two major manufacturers, Broadcom and NVIDIA, dominate the market. With their differentiated technical designs, both meet the scenario needs of different smart computing centers.
1.Broadcom Tomahawk 5 Series
In 2022, Broadcom launched the industry's first commercial 51.2T capacity switch chip, Tomahawk 5, marking the entry of network chips into the 5nm era. Using Monolithic bare die packaging technology, this chip achieves a major breakthrough in balancing performance and energy consumption — the power consumption per 100Gbps transmission bandwidth is less than 1W, representing a 95% energy efficiency improvement compared to the previous-generation Tomahawk 4 (20W/100G).
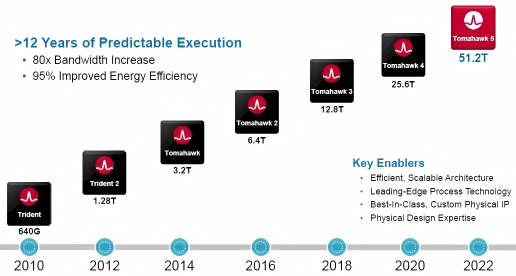
Figure 2: Broadcom Technology Roadmap
In terms of packaging and optical module compatibility, the Tomahawk 5 series has made further breakthroughs: The basic version of Tomahawk 5 supports traditional pluggable optical modules and is also compatible with CPO (Co-packaged Optics) technology. Compared to traditional pluggable optical modules, CPO packaging reduces insertion loss by over 30% and cuts per-port cost by more than 80%, and lower energy consumption by 50%, perfectly meeting the high energy efficiency and low cost needs of smart computing centers.
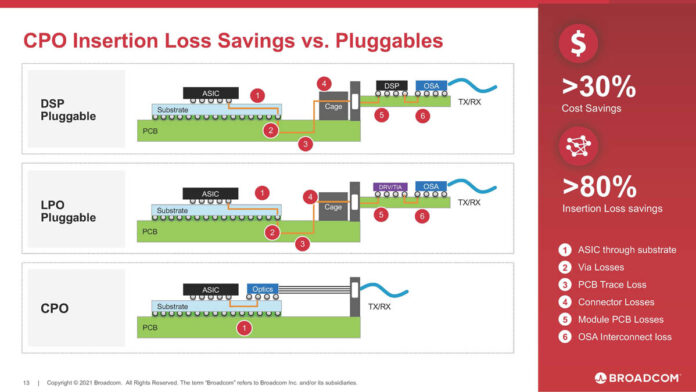
Figure 3: This diagram compares CPO and traditional pluggable optical modules, illustrating CPO's advantages in insertion loss and cost - key for smart computing centers' energy efficiency goals.
In terms of port configuration, Tomahawk 5 supports flexible combinations of multiple specifications, including 64 ports of 800Gbps, 128 ports of 400Gbps, and 256 ports of 200Gbps. It can quickly build an adaptive network environment based on the scale and business needs of smart computing centers.
2.NVIDIA Spectrum-4 Platform
In 2022, NVIDIA launched the next-generation Ethernet platform, NVIDIA Spectrum-4. It is not a single chip product but an integrated "chip + network card + DPU + software" solution. Composed of the Spectrum-4 switch series, ConnectX-7 network cards, BlueField-3 DPU, and DOCA data center infrastructure software, it aims to significantly improve the operational efficiency of large-scale cloud-native applications and AI services through hardware acceleration & software collaboration.

Figure 4: NVIDIA Spectrum-4 Ethernet Switch
In terms of core performance, the Spectrum-4 platform has three key highlights:
Ultra-high bandwidth density: The SN5000 switch supports up to 128 × 400GbE ports or 64 × 800GbE ports, with a total bandwidth of 51.2T, meeting the interconnection needs of ultra-large-scale smart computing centers.

Figure 5: NVIDIA Spectrum-4 with 64 × 800G Ports
Strong data processing capability: A single chip integrates 3.76 billion transistors, with a packet processing rate of 100Bpps (100 billion packets per second), enabling rapid processing of massive small packets in AI training.
Security acceleration function: It has a built-in hardware-level encryption module, supporting real-time encryption during data transmission to ensure the core data security of smart computing centers.
In addition, through in-depth collaboration with NVIDIA GPUs and DPUs, the Spectrum-4 platform can realize intelligent scheduling of network traffic, reducing bottlenecks in data transmission. It is particularly suitable for distributed training scenarios of large AI models.
3.Core Technical Support for 51.2T Switches: 112G SerDes
112G SerDes (Serializer/Deserializer) is the core technology enabling ultra-high bandwidth transmission in 51.2T switches. A 51.2T switch requires 512 independent 112G SerDes channels. For example, an 800G port aggregates 8×112G channels (896Gbps raw speed, adapted to 800G standards), and a 400G port uses 8×56G half-rate channels, directly enabling the switch's ultra-high port density. Through advanced modulation methods and signal processing capabilities, it breaks the speed limit of traditional SerDes and provides a high-speed and stable transmission foundation for smart computing center networks.

Figure 6: Market Trends of 112G SerDes
4.Technical Principles and Advantages
112G SerDes mainly adopts PAM4 (4-level Pulse Amplitude Modulation) technology. By transmitting 2 bits of data in a single signal cycle (traditional NRZ modulation only transmits 1 bit), it achieves full-rate transmission of 112Gbps. At the same time, it is compatible with the traditional NRZ (Non-Return-to-Zero) modulation method and can switch to 56Gbps half-rate transmission, meeting both high-speed and compatibility requirements. Its core advantages are reflected in:
High bandwidth density: The speed of a single 112G SerDes channel is equivalent to that of 2 56G SerDes channels, enabling higher bandwidth within the same chip area.
Low signal loss: By optimizing signal encoding and equalization technologies, it reduces noise interference during transmission and improves the signal transmission distance.
Flexible adaptation: It supports switching between full-rate and half-rate, and can be flexibly configured according to port requirements (800G/400G).
5.Practical Application Scenarios
In 51.2T switches, the application of 112G SerDes directly determines the port speed:
800G port: 8 × 112G SerDes channels are used for parallel transmission at full rate (112Gbps), with a total speed of 896Gbps (actually adapted according to the 800G standard).
400G port: 8 × 112G SerDes channels are used for transmission at half rate (56Gbps), with a total speed of 448Gbps (actually adapted according to the 400G standard).
In addition, 112G SerDes is also widely used for interconnection between computing devices and network devices, such as high-speed data transmission between CPUs, GPUs, AI accelerators, network cards, and switches. This ensures end-to-end low-latency transmission within smart computing centers.
II. Application Scenarios and Networking Solutions of 51.2T Switches
The application scenarios of 51.2T switches are highly focused on high bandwidth and low latency requirements, covering two core fields: large AI model training and ultra-large-scale data center interconnection. Its networking solutions, through a two-tier architecture and flexible optical module configuration, realize efficient and scalable network deployment.
Core Application Scenarios
Large AI model training scenario: Distributed training of large AI models (such as GPT-4) requires the collaboration of multiple GPU servers. Each server needs to transmit massive parameters and training data in real time, which places extremely high demands on network bandwidth and latency. Through 400G/800G high-speed interconnection, 51.2T switches can reduce the data transmission waiting time between GPUs and reduce the AI model training cycle by 30%-50% compared to networks using 25.6T switches.
Spine/Leaf interconnection in ultra-large-scale data centers: Traditional ultra-large-scale data centers (with more than 10,000 servers) adopt a three-tier Spine/Leaf architecture, which has problems of multiple levels and high latency. 51.2T switches support a two-tier Spine/Leaf architecture — Leaf-layer switches are directly connected to servers, and Spine-layer switches realize interconnection between Leaf layers. This can support the interconnection needs of tens of thousands of GPUs while reducing network latency by 20%-30%.
III.Typical Networking Solutions and Optical Module Configuration
The networking solutions of 51.2T switches are divided into two categories based on port speed. Different solutions correspond to differentiated optical module configurations to meet the needs of different transmission distances.
1.Solution 1: 64×800G Switch (Large AI Model Training Scenario)
Application scenario: Interconnection between the Spine layer and Leaf layer of large AI model training clusters, requiring 800G high-speed transmission.
Optical module selection: Equipped with 800G OSFP or QSFP-DD800 packaged optical modules, different models are adapted according to transmission distance. OSFP supports higher power (up to 15W) for long-distance modules, while QSFP-DD800 is backward compatible with existing QSFP56 ports, reducing upgrade costs for enterprises.
- Short distance (≤50m): Choose 800G SR8 optical modules, using multimode optical fibers, suitable for interconnection within a cabinet or between adjacent cabinets.
- Medium distance (50m-500m): Choose 800G DR8 optical modules, using single-mode optical fibers, suitable for cross-regional interconnection within data centers.
- Long distance (≤2km): Choose 800G 2×FR4 optical modules, using wavelength division multiplexing technology, suitable for inter-building interconnection in data centers.
2.Solution 2: 128×400G Switch (Ultra-Large-Scale Data Center Scenario)
Application scenario: Spine-layer interconnection in ultra-large-scale data centers, or Leaf-layer connection to 400G servers.
Optical module selection: Equipped with 400G OSFP or QSFP112 packaged optical modules, with adaptation according to transmission distance:
- Short distance (≤50m): 400G SR4 optical modules, multimode optical fibers.
- Medium distance (50m-500m): 400G DR4 optical modules, single-mode optical fibers.
- Long distance (≤2km): 400G FR4 optical modules, single-mode optical fibers.
3.Switch Side - Network Card Side Adaptation of Optical Modules
In the networking of 51.2T switches, the optical modules on the switch side and network card side must be accurately adapted to ensure stable data transmission:
Switch side: 64 × 800G switches use 800G OSFP 2×SR4/2×DR4/2×FR4 optical modules; 128 × 400G switches use 400G QSFP112 VR4/SR4/DR4/FR4 optical modules.

Figure 7: AICPLIGHT 800GBASE 2xSR4/SR8 OSFP Optical Transceiver Module
Network card side: Regardless of the networking solution adopted, 400G QSFP112 SR4/DR4 or 400G OSFP SR4/DR4 optical modules are uniformly used to reduce the configuration complexity and cost on the network card side.

Figure 8: AICPLIGHT 400GBASE-SR4 OSFP Optical Transceiver Module
IV.Conclusion
With its core advantages of high bandwidth, low latency, low energy consumption, and low cost, the 51.2T RoCE switch solves the network pain points of smart computing centers in large AI model training and ultra-large-scale data processing. From a technical perspective, it relies on 112G SerDes and CPO packaging technology to achieve speed breakthrough and energy efficiency optimization. From an application perspective, through flexible networking solutions and optical module configurations, it adapts to the needs of smart computing centers of different scales. In the future, as large AI models evolve towards trillion-level parameters and real-time interaction, 51.2T switches will be further upgraded. Through more highly integrated chip designs, more advanced optical interconnection technologies (such as CPO 2.0), and more intelligent traffic scheduling algorithms, they will continue to lead the network innovation of smart computing centers and become a key infrastructure in the digital economy era.
