 English
English
As AI large models evolve towards the trillion-parameter scale, the demand for interconnect network bandwidth, latency, and scalability in computing clusters has become unprecedentedly stringent. The InfiniBand (IB) network, with its inherent advantages of low latency and high bandwidth, has become the core foundation for LLM training.
Currently, NDR (Next Data Rate, 400G IB) is the mainstream high-performance interconnect solution, while XDR (eXtreme Data Rate, 800G IB) is the new-generation benchmark technology. They exhibit significant generational differences in terms of networking architecture, hardware specifications, and optical module compatibility. This article focuses on the DGX SuperPOD architecture, systematically breaks down the technical characteristics of NDR vs. XDR, and highlights the logic behind optical module selection, providing a clear reference for networking decisions in AI clusters of different scales.
SuperPOD Architecture and Track Optimization: The Common Networking Foundation for NDR and XDR
The DGX SuperPOD architecture is a combination of NVIDIA DGX systems, InfiniBand and Ethernet, management nodes, and storage. The SuperPOD reference design introduces a computing building block called the Scalable Unit (SU), enabling the modular deployment of the DGX SuperPOD GPU cluster, which can be extended to hundreds of nodes.
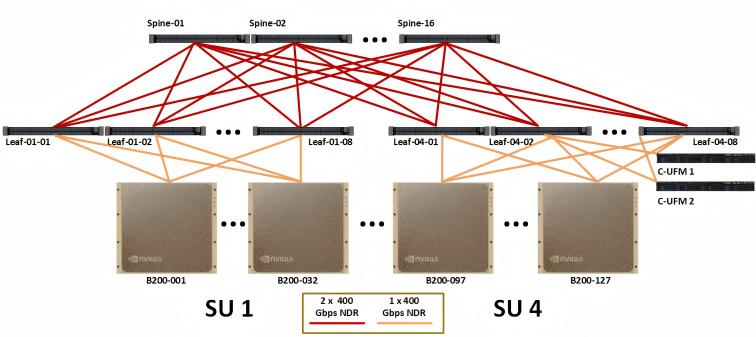
Figure 1: Compute fabric for full 127-node DGX SuperPOD (Source: NVIDIA)
Core Advantages: PXN and Rail Optimization
NCCL (NVIDIA Collective Communications Library) is topology-aware and optimized for high bandwidth and low latency across PCIe, NVLink, Ethernet, and InfiniBand interconnects.
A new feature introduced in NCCL 2.12 is PXN (PCI x NVLink), which allows GPUs to communicate with NICs on the node via NVLink and then PCI. This eliminates the need to pass through the CPU using QPI or other inter-CPU protocols, which cannot provide full bandwidth.
In a rail-optimized network topology, each DGX system's NIC-0 connects to the same Leaf switch (L0), NIC-1 connects to the same Leaf switch (L1), and so forth. This design maximizes all-reduce performance while minimizing network interference between flows. It also lowers network costs by reducing connections between rails.
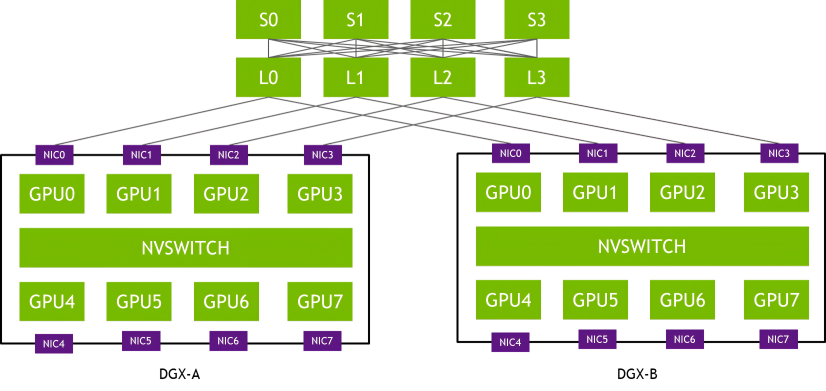
Figure 2: Rail-optimized network topology (Source: NVIDIA)
PXN utilizes the NVIDIA NVSwitch connections between GPUs within a node to first move data from a GPU onto the same track as the destination, and then sends it without crossing rails. This enables message aggregation and network traffic optimization.
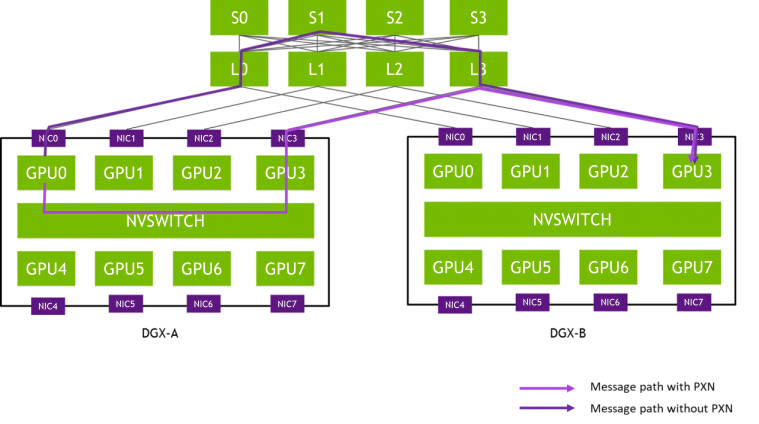
Figure 3: Example message path from GPU0 in DGX-A to GPU3 in DGX-B (Source: NVIDIA)
NDR (400G IB) Network: The Mainstream Choice for Small-to-Medium AI Clusters
Based on the SuperPOD architecture, NDR (400G IB) is built on the NVIDIA Quantum-2 platform. With its proven performance and flexible optical module compatibility, it is the preferred solution for training models with hundreds of billions of parameters and for small-to-medium-scale clusters(≤256 nodes).
1.Key Hardware Specifications
| Parameter | Specification |
|---|---|
| NDR Switch | Quantum-2 Series (QM9700/QM9790) |
| Port Configuration | 32 OSFP slots, supporting 64 x 400Gb/s (NDR) ports or 128 x 200Gb/s (NDR200) ports |
| Total Aggregate Bandwidth | 51.2 Tb/s |
| Core Technology | Third-generation SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) |
| NDR Network Card | ConnectX-7 |
| Port Performance | 400Gb/s (NDR) throughput using 100Gb/s SerDes |
| Message Rate | 330-370 Million messages per second |
| Compatibility | 32 PCIe Gen5 lanes (backward compatible with Gen4/Gen3) |
2.Optical Module and Copper Cable Adaptability
The core advantage of NDR switches is their compatibility with multiple types of transmission media, allowing flexible selection based on distance.
- Optical Modules: Supports both single-mode (SM) optical modules (for distances > 100m) and multimode (MM) optical modules (for distances≤100m) to balance cost and signal stability.
- Copper Cables: Supports Direct Attach Copper (DAC) cables up to 5m, suitable for short-distance connections between adjacent equipment (e.g., switches and servers in the same cabinet), offering flexible, low-cost deployment.
3.NDR Networking Reference: Node-to-Switch Ratio
Based on the SuperPOD track-optimized / fat-tree architecture, the equipment ratio for different cluster scales is defined.
| SU Count | Node Count | GPU Count | InfiniBand Switch Count (Leaf) | InfiniBand Switch Count (Spine) | InfiniBand Switch Count (Core) |
|---|---|---|---|---|---|
| 2 | 64 | 512 | 16 | 8 | - |
| 4 | 128 | 1024 | 32 | 16 | - |
| 8 | 256 | 2048 | 64 | 32 | - |
| 16 | 512 | 4096 | 128 | 128 | 64 |
Clusters exceeding 4 SUs (256 nodes) require the introduction of core spine switches, adopting a 3-layer architecture. The maximum scale for the 2-layer architecture is 256 nodes (2048 GPUs).
XDR (800G IB) Network: The Core Enabler for Hyperscale AI Factories
XDR (800G IB) is built on the NVIDIA Quantum-X800 platform. As XDR networks scale, they rely heavily on 800G single-mode optics. You can explore the technical reasons in why XDR networking relies on 800G single-mode optical transceivers.With 800Gb/s end-to-end bandwidth, stronger scalability, and specialized hardware design, it is the next-generation technology supporting trillion-parameter model training and hyperscale clusters (> 256 nodes). It is also compatible with previous NDR/HDR infrastructure.
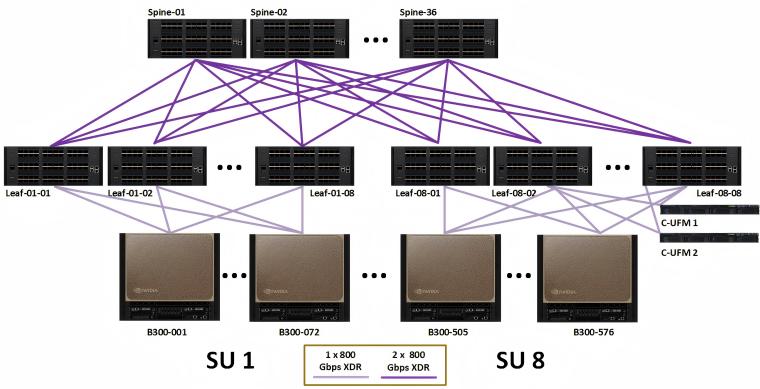
Figure 4: Compute fabric for full 576-node DGX SuperPOD (Source: NVIDIA)
1.Key Hardware Specifications
| Parameter | Specification |
|---|---|
| XDR Switch | Quantum-X800 Series (Q3400/Q3200) |
| Port Configuration (Q3400) | 72 OSFP slots, breaking out into 144 x 800Gb/s ports |
| Scalability (Q3400) | 2-layer Fat-Tree theoretical lossless support for 10,368 nodes / 2,592 actual nodes (20,000 GPUs) |
| Core Technology | Fourth-generation SHARP (SHARPv4), Adaptive Routing, Telemetry-based Congestion Control |
| XDR Network Card | ConnectX-8 SuperNIC |
| Port Performance | 800Gb/s throughput |
| Message Rate | 450 Million packets per second |
| Compatibility | Supports PCIe Gen6 (backward compatible with Gen5/Gen4/Gen3) |
| Dedicated Design | Includes a dedicated UFM (Unified Fabric Manager) port, simplifying deployment (unlike NDR, which requires planning for port allocation) |

Figure 5: Quantum-X800 XDR switch series include a dedicated UFM port (Source: NVIDIA)
2.Optical Module and Copper Cable Adaptability
XDR focuses on high-performance, long-distance transmission, making the selection of transmission media more focused,When selecting optical modules for XDR deployments, understanding the difference between DR4 and breakout architectures is critical. See detailed comparison: 800G DR4 vs 2×DR4 OSFP transceiver.
- Optical Modules: Only supports 800G single-mode optical modules (e.g., OSFP224 SM modules). This leverages the low-loss characteristics of single-mode fiber to meet the demand for cross-data center, long-distance transmission (> 100m) required by distributed hyperscale clusters.
- Copper Cables: Only supports DAC cables up to 1.5m, limited to extremely short-distance connections (e.g., between a switch and a management node in the same cabinet).
3.XDR Networking Advantages: Cost and Scalability Breakthroughs
Compared to NDR, XDR offers significant advantages in large-scale clusters:
- Wider 2-Layer Architecture Coverage: The 2-layer architecture can support up to 2,592 nodes (20,000 GPUs) without prematurely introducing a 3-layer architecture, reducing equipment layers and potential failure points.
- Significant Cost Advantage: As the number of nodes increases, XDR networking costs are reduced by over 40% compared to NDR (e.g., a 1024-node cluster requires fewer XDR switches and optical modules).
Comparison of Core Differences: NDR vs. XDR
| Comparison Dimension | NDR (400G IB) | XDR (800G IB) |
|---|---|---|
| Core Bandwidth | Single Port 400Gb/s | Single Port 800Gb/s |
| Switch Platform | NVIDIA Quantum-2 (QM9700/QM9790) | NVIDIA Quantum-X800 (Q3400/Q3200) |
| Network Card Model | ConnectX-7 | ConnectX-8 SuperNIC |
| Message Rate | Single Port 330-370M / second | Single Port 450M / second |
| Optical Module Characteristic | Supports SM + MM, adapts to short-distance cost control and long-distance stable transmission | Only supports SM, focuses on low-loss, high-performance long-distance transmission |
| Copper Cable Max Length | Max 5m, flexible for short-distance scenarios | Max 1.5m, only for extremely short-distance connections |
| Max 2-Layer Scale | 256 Nodes (2048 GPUs) | Actual 2,592 Nodes (20,000 GPUs) |
| Dedicated Design | No dedicated UFM port, requires planning for access location | Includes a dedicated UFM port, simplifying deployment |
| Core Application Scenario | Hundreds-of-billions-of-parameter models, Small-to-Medium AI Clusters (≤256 nodes) | Trillion-parameter models, Hyperscale AI Factories (>256 nodes) |
Conclusion
From NDR's flexible adaptability to XDR's performance breakthrough, the iteration of InfiniBand networks consistently follows the escalation of AI computing demands.
- Short-Term Selection: For small-to-medium-scale clusters (≤256 nodes) or budget-constrained scenarios, prioritize NDR. Its compatibility with single-mode/multimode optical modules and flexible 5m copper cable deployment balances performance and cost, and it can be rapidly deployed based on a mature ecosystem.
- Long-Term Strategy: For hyperscale clusters (> 256 nodes) or trillion-parameter model training needs, XDR is the inevitable choice. The 800Gb/s bandwidth, 2,592-node 2-layer scalability, and 40%+ cost advantage support the continuous expansion of AI factories, with a smooth upgrade path due to NDR infrastructure compatibility.
The selection of optical modules, a core carrier of the difference between the two, must be closely tied to the scenario: NDR requires flexible matching of single-mode/multimode optical transceivers based on transmission distance, while XDR must focus on the low-loss advantage of 800G single-mode optical transceivers.
