 English
English
The generative AI revolution has shifted the bottleneck of the data center from the CPU to the GPU, and now, from the GPU to the Network. As Large Language Models (LLMs) scale toward tens of trillions of parameters, the underlying fabric must evolve to handle unprecedented east-west traffic. This imperative is the genesis of the NVIDIA Quantum-X800 InfiniBand platform, a massive architectural leap that introduces the world's first end-to-end 800Gb/s (800G) networking solution.
At the heart of this throughput explosion is a specific physical interconnect standard: OSFP224. In this deep dive, we explore why the transition to 224G SerDes is the "secret sauce" behind the Quantum-X800's performance and what IT architects need to know about deploying these high-density optics.
The Architectural Shift: From 112G to 224G SerDes
To understand the logic of 800G OSFP224, we must first examine the SerDes (Serializer/Deserializer). This is the fundamental technology that converts parallel data from the switch silicon into high-speed serial data for transmission over optical fibers or copper cables.
In the previous generation (Quantum-2 / 400G), the industry standard was 112G SerDes. To achieve 400Gb/s, the system used four channels of 112G (4 x 100G effectively). While 800G can be achieved using eight channels of 112G (8 x 100G), this approach quickly hits a "density wall." In massive GPU clusters, doubling the number of lanes to 8x100G leads to unsustainable power consumption and exhausts the available physical space within standard switch and server form factors.
NVIDIA Quantum-X800 shatters this barrier by standardizing on 224G SerDes technology. By doubling the speed of each electrical lane to 224Gbps, the OSFP224 form factor can deliver 800G throughput using only half the available lanes (e.g., a 4x200G configuration). This lane efficiency is not merely a speed bump; it is the critical enabler that allows the same physical cage to sustain current 800G needs while providing a clear, backward-compatible roadmap to future 1.6T (1600G) networking when all eight lanes are utilized. This transition mandates extreme precision in signal integrity (SI) and advanced Forward Error Correction (FEC) to manage the noise inherent at such high frequencies.
For further insights of 112G and 224G SerDes, see 224G SerDes vs 112G: How It Enables 800G and 1.6T Optical Modules for AI Data Centers.
NVIDIA Quantum-X800: The Magic of Twin-Port OSFP in the 144-Port Powerhouse
The Quantum-X800 (specifically the Q3400-RA switch series) is designed to be the "central nervous system" of the AI Factory, achieving a staggering 115.2 Tb/s of aggregate bi-directional throughput in a compact form factor. The true "magic" behind this density is the synergy of the 224G lane rate with a sophisticated Twin-Port OSFP224 architecture.
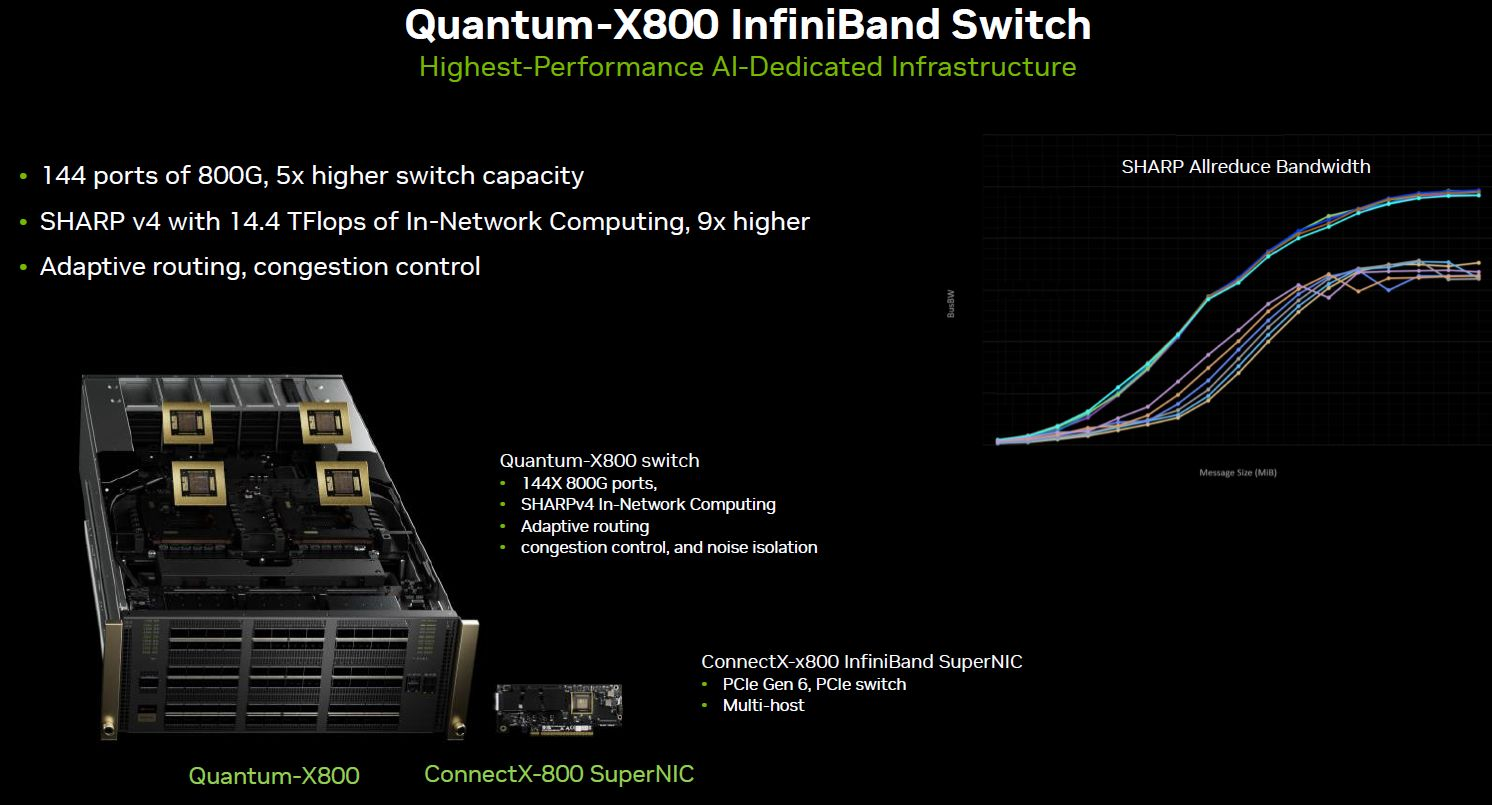
Figure 1: Quantum-X800 Q3400-RA InfiniBand switch (144 x 800G)
A standard OSFP cage traditionally houses a single optical transceiver. However, by leveraging 224G SerDes, the Quantum-X800 can utilize a "Twin-Port" configuration. In this scenario, a single OSFP cage can host a module—such as an OSFP-1.6T-2DR4 (1.6T 2xDR4/DR8 OSFP224 Optical Transceiver)—that breaks out into two independent 800G InfiniBand logical ports. This ingenious logical decoupling treats the eight lanes (8x224G) as two separate four-lane interfaces (2x4x200G). This effectively doubles the port count of a 4U switch from 72 to 144 independent 800G ports, a concept often referred to as doubling the switch "Radix" (the number of ports per switch). For data center operators, a higher Radix simplifies network topology by drastically reducing the number of switch layers (Hops) needed to connect thousands of GPUs, which is essential for slashing the collective communication latency that dictates AI training performance.

Figure 2: Point-to-point link from an NVIDIA Quantum-X800 Q3400-RA switch, which leverages its OSFP224 twin-port configuration to host an OSFP-1.6T-2DR4 transceiver, connecting via two MPO-12/APC Elite trunk cables (≤500M OM4 fiber) to dual OSFP-800G-DR4 transceivers for breakout to two NVIDIA C8180 800Gbps NICs installed within a B300 server.
Cooling and Form Factor: IHS vs. RHS
As the power consumption of each 800G OSFP module approaches 20W–30W, thermal management is no longer an afterthought but a primary design constraint. The OSFP standard adopted in the Quantum-X800 addresses this through two distinct physical architectures that are often confused.
OSFP-IHS (Integrated Heat Sink)
Also known as the "Finned" top. These modules have built-in cooling fins that protrude from the module into the airflow path.
Application: Required for the Quantum-X800 switch side.
Why: The switch relies on high-velocity air being pulled across these fins to dissipate the intense heat generated by 144 ports of 800G traffic.
OSFP-RHS (Riding Heat Sink)
Also known as the "Flat" top. These modules do not have fins; instead, they rely on a "riding" heat sink built into the device cage or a cold-plate in liquid-cooled environments.
Application: Primarily used in ConnectX-8 NICs or BlueField-3/4 DPUs inside servers where space is at a premium.
Crucial Deployment Tip: You cannot mix these haphazardly. Plugging an RHS module into an IHS-optimized switch cage will result in immediate overheating and potential hardware damage due to the lack of surface area for air cooling.
For deeper understanding of OSFP thermal form factors, refer to our guide: OSFP-IHS vs. OSFP-RHS and OSFP Thermal Form Factors Explained: Finned Top, Closed Top, and Flat Top (RHS).
Beyond Bandwidth: In-Network Computing with SHARPv4
Bandwidth is only half the story. In AI training (All-Reduce, All-to-All operations), the network spends a lot of time "calculating" data rather than just moving it.
The Quantum-X800, powered by the 800G OSFP224 interconnect, integrates NVIDIA SHARPv4 (Scalable Hierarchical Aggregation and Reduction Protocol).
In-Network Computing: Instead of GPUs sending raw data back and forth to average gradients, the Quantum-X800 switch performs these mathematical operations in the network fabric at wire speed.
Impact: SHARPv4 provides a 9x increase in bandwidth for collective operations compared to the previous generation. By moving the "math" to the OSFP224 lanes, the GPU's HBM (High Bandwidth Memory) is freed up for actual computation rather than communication overhead.
Conclusion
The NVIDIA Quantum-X800 with 800G OSFP224 is designed to ensure that the network is never the bottleneck. By doubling the SerDes rate, leveraging Twin-Port architectures for unprecedented density, and offloading compute tasks to the switch, NVIDIA has created a fabric that allows AI models to scale linearly. The industry's forward-looking adoption of the OSFP224 standard adopted by the Quantum-X800 ensures future-proofing; because the electrical interface is already validated for 224G per lane, the transition to native 1.6T networking will not require a new physical form factor.
